[정리] Redis Cluster
레디스의 처리량, 가용성 개선을 동시에 달성
레디스를 운영하며 eviction이 자주 발생한다면, 서버의 메모리를 증가시키는 방식의 스케일 업을 고려할 수 있다.
왜냐하면 eviction은 인스턴스의 maxmemory 만큼의 데이터가 가득 찼을 때 데이터를 저장 시 발생하는 것이므로, 서버의 메모리를 늘리고 maxmemory수치를 늘린다면 어느 정도 해소가 가능하다.
하지만 이 메모리를 늘리는 확장 방식은 eviction은 방지해주지만 레디스의 처리량 개선에는 미미하다.
레디스는 단일 스레드로 요청을 처리하기에 CPU를 추가해도 멀티 코어를 활용 못한다.
그러면 처리량은 어떻게 개선할 수 있을까? 바로 데이터를 분산 시켜 여러 레디스 인스턴스에서 관리하면 다수의 서버에서 병렬 처리가 가능해 처리량을 늘릴 수 있다.
게다가 이런 처리량 개선 + 센티널과 다른 방식으로 고가용성 달성을 이룰 수도 있다.
레디스 클러스터 기능
레디스의 클러스터 모드를 쓰면 이런 이점을 누릴 수 있다.
- 수평 확장: 애플리케이션단의 수정 없이 레디스 인스턴스 수평 확장 가능
- 샤딩: 레디스 데이터를 여러 마스터 노드에 분산 저장
- 고가용성 및 복제: 노드 장애에도 서비스 지속 가능
- 자동 페일오버: 장애 발생 시 복제본이 마스터로 자동 승격
데이터 샤딩
데이터 저장소를 수평 확장시켜 여러 서버 간에 데이터를 분할해 관리하는 데이터베이스 아키텍처 패턴을 샤딩(Sharding) 이라 한다.
 레디스의 클러스터 기능은 다음의 특징이 있다.
레디스의 클러스터 기능은 다음의 특징이 있다.
- 마스터를 최대 1,000개 까지 확장 가능
- 샤딩과 관련된 기능은 레디스 자체적으로 관리(추가 아키텍처 불필요)
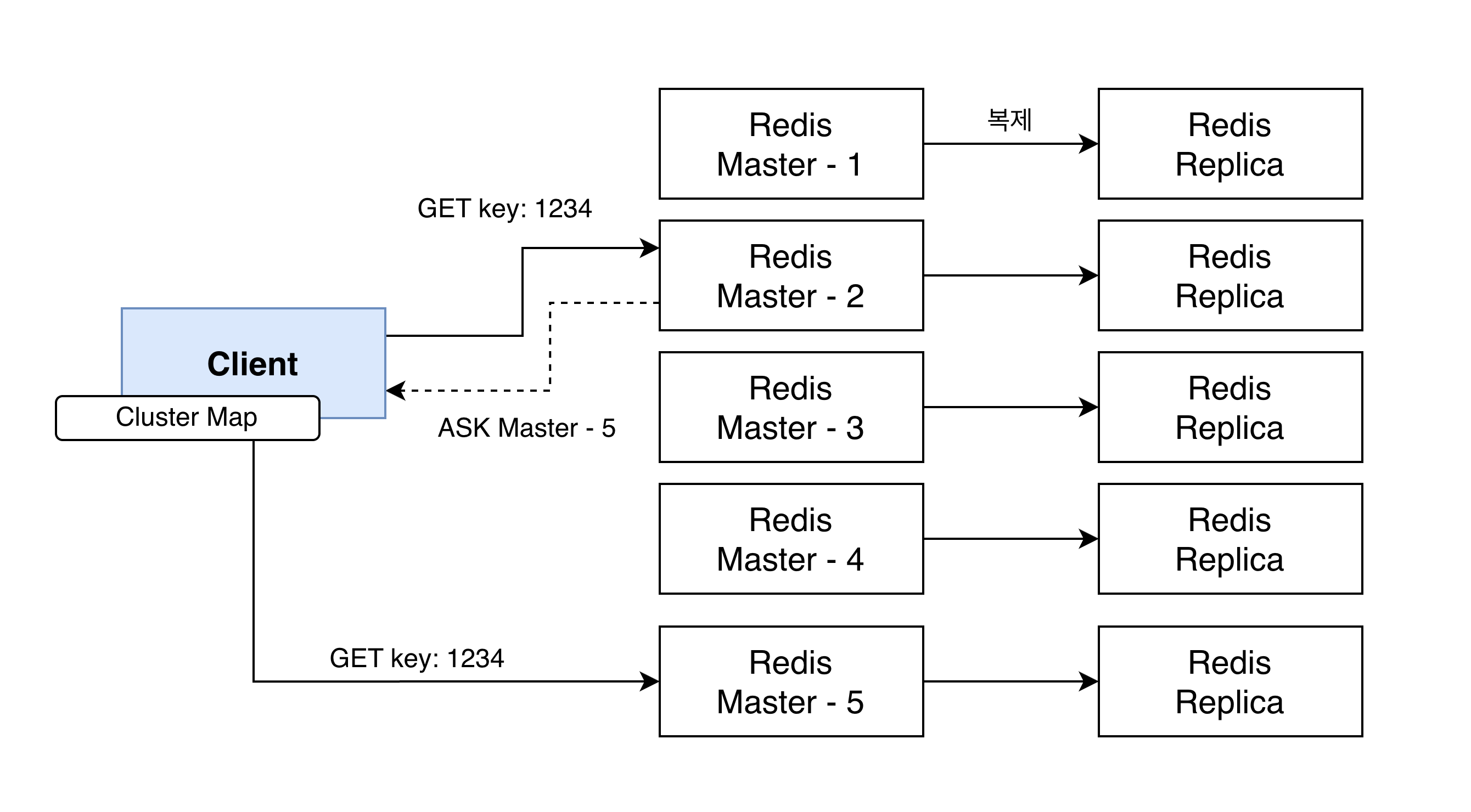
클러스터에서 데이터는 키를 이용해 샤딩되며, 하나의 키는 항상 하나의 마스터 노드와 매핑된다. 클러스터의 모든 노드는 키가 저장되야 할 노드를 알고 있기에 클라이언트가 다른 노드에 데이터를 읽거나 쓸 때 해당 키가 할당된 마스터 노드로 리다이렉션한다.
이 과정은 레디스 노드와 애플리케이션단의 레디스 클라이언트 라이브러리에서 자동 처리된다. 애플리케이션의 소스 코드 수정 없이 미리 구현된 프로토콜을 따르기에 개발자 입장에서 번거로움이 적다.
또한, 매번 레디스에 키를 저장할 노드를 질의하지 않으려고 클라이언트에서는 클러스터 내에서 특정 키가 어떤 마스터 노드에 저장되어있는지를 캐싱해둘 수 있다.
고가용성
레디스 클러스터는 최소 3대의 마스터, 3대의 복제본 노드를 가지도록 구성하는게 일반적이라 한다.
같은 클러스터 소속 노드끼리는 서로를 모니터링한다.
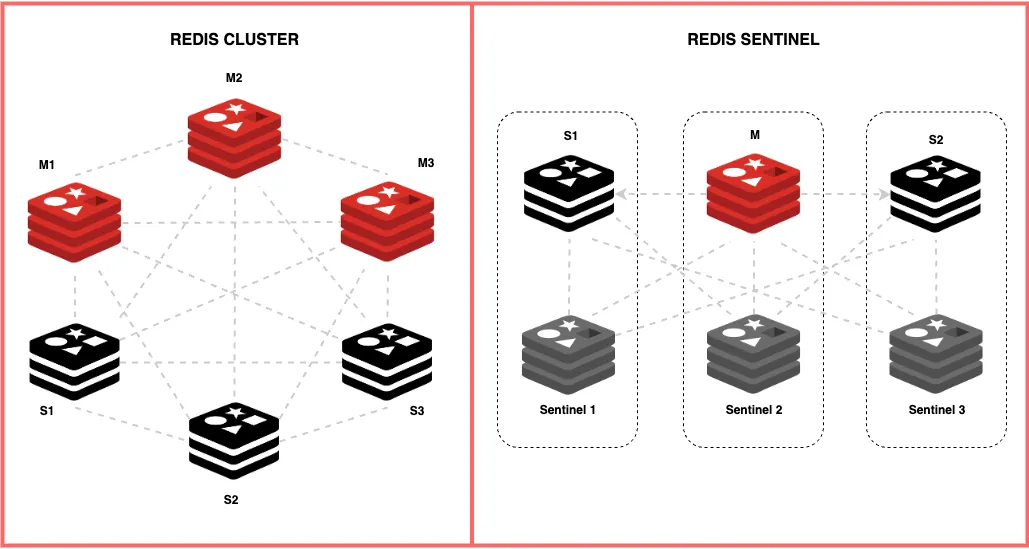
출처: https://medium.com/@harishsingh8529/the-hidden-bottlenecks-in-redis-clusters-at-scale-45c35593227f
마스터 노드에 장애가 발생하면 이를 인지한 다른 노드들이 마스터에 연결됐던 복제본을 마스터로 승격시키는 자동 페일오버가 되기에 개발자 개입 없이 복구가 가능(가용성 up)하다. 또한 마스터에 연결된 복제본 개수를 파악해서 잉여 복제본을 다른 필요한 마스터 노드에 연결시키는 복제본 마이그레이션 작업도 한다.
노드 간 감시 등을 위해선 당연히 서로 간 통신이 필수인데 이를 위해 노드들은 클러스터 버스라는 독립적인 통신을 쓴다.
클러스터 내 레디스 인스턴스들은 다른 레디스들과 통신을 위한 TCP 포트가 열려 있다.
클라이언트로 부터 커맨드를 받는 TCP 포트와 독립되게 동작하며, 설정에서 cluster_bus_port를 따로 정의하지 않는다면 일반포트에 10,000을 더한 값으로 설정된다.
풀 메쉬 토폴로지 형태지만 가십 프로토콜과 구성 업데이트 메커니즘으로 클러스터가 정상일때는 노드간 많은 메시지는 교환하지 않는다한다.
레디스 클러스터 동작 방식
해시슬롯을 이용한 데이터 샤딩
클러스터 구조에서 모든 데이터는 해시슬롯에 저장된다. 총 16,384개의 슬롯이 존재하며, 각 마스터 노드는 이 슬롯을 나누어 가진다.
3대의 마스터 노드로 클러스터를 구성했을 때 다음과 같이 해시슬롯이 분배된다.
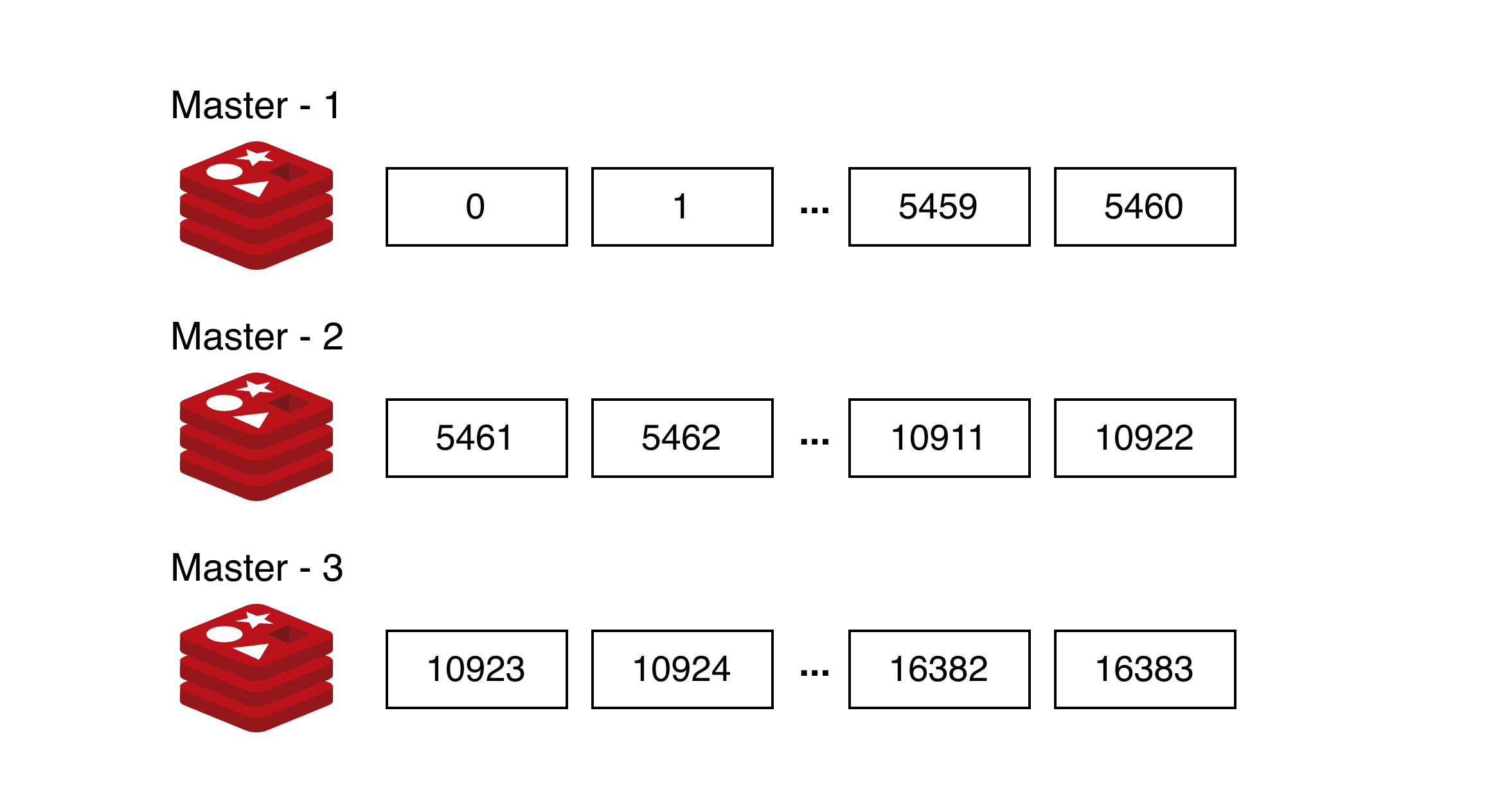
레디스에 입력되는 모든 키는 하나의 해시슬롯과 매핑되며 이때 사용되는 해시함수는 다음과 같다.
HASH_SLOT = CRC16(key) mod 16384
키를 CRC16으로 먼저 암호화한 다음 16384로 나눈 나머지 값을 이용해 해시슬롯이 결정된다. 데이터 저장, 읽을 때 위의 함수를 이용해 커맨드를 처리할 마스터 노드를 찾아간다.
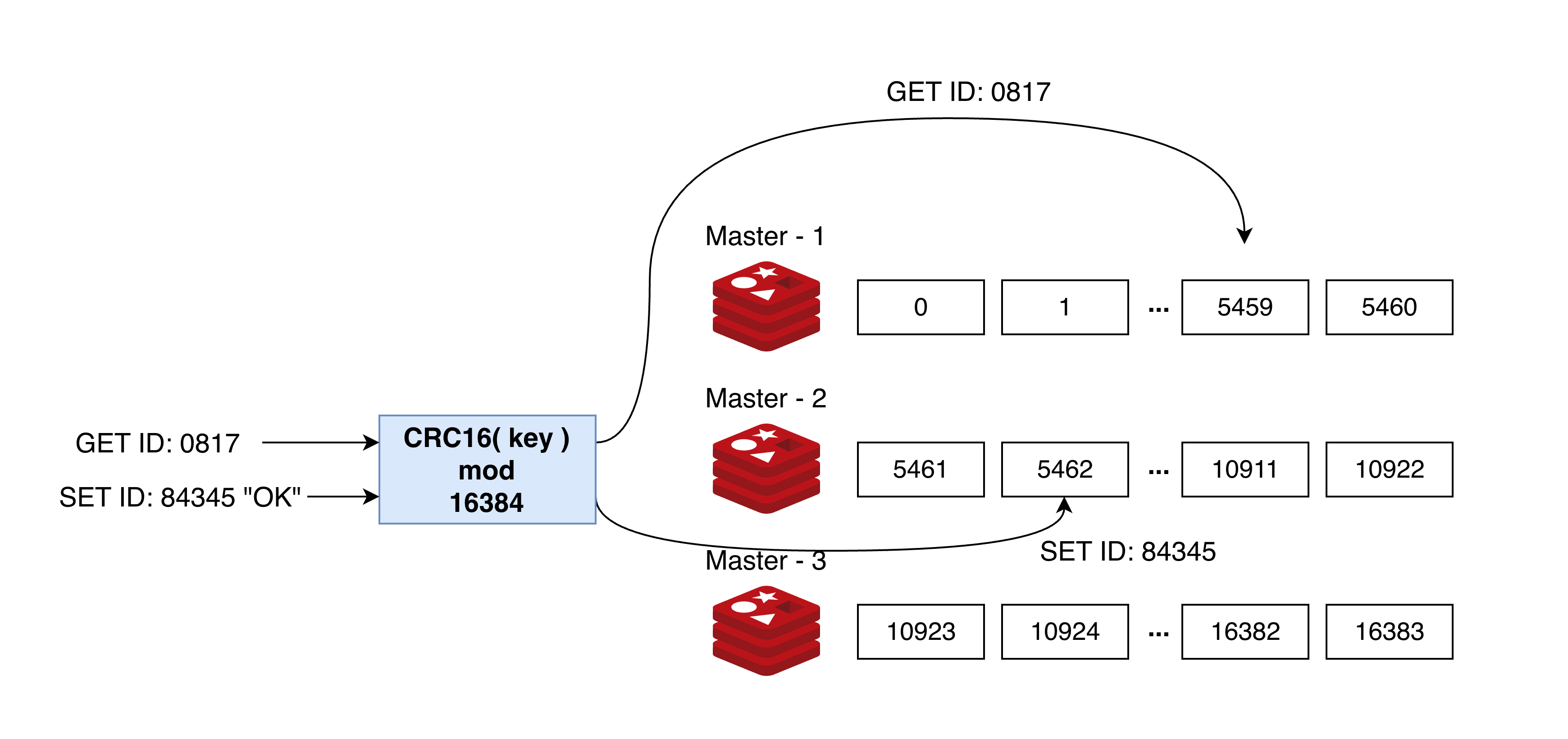
위 예시를 보면 ID:0817 이라는 키를 가지고 올 때, 알고리즘에 의해 키는 5459 라는 해시슬롯에 저장되어 있음을 알 수 있다.
따라서 클라이언트는 해시슬롯 5459를 가지고 있는 마스터 1에서 데이터를 가지고 올 수 있도록 한다.
ID:87345 라는 키에 데이터를 저장할 때는 우선 키가 저장될 해시슬롯이 5462 라는 것을 먼저 계산한다.
그 뒤, 해당 해시슬롯을 갖고 있는 마스터 2에 데이터를 저장한다.
해시 슬롯은 마스터 노드 내에서 자유롭게 옮겨질 수 있으며, 옮겨지는 중에도 데이터는 정상적으로 접근 가능하다. 이런 특성으로 한 클러스터 내의 마스터 노드의 추가, 삭제는 간단히 처리될 수 있다.
마스터가 3개인 클러스터 노드에 1개의 마스터 노드 추가는 신규 레디스 노드를 마스터로 추가한 뒤 기존 노드가 가지고 있던 해시슬롯의 일부를 신규 마스터로 이동시켜주면 된다. 삭제도 간단한데 삭제할 노드가 갖고 있는 해시슬롯을 전부 다른 마스터로 이동시킨다음 노드를 클러스터에서 제외시키면된다.
해시태그
클러스터를 사용할 때는 다중 키 커맨드를 사용할 수 없다.
다중 키 커맨드는 MGET과 같이 한 번에 여러 키에 접근해 데이터를 가져오는 커맨드.
MGET user1:name user2:name
위 커맨드를 쓰면 user1:name, user2:name에 대한 값을 한 번에 가져올 수 있다.
하지만 레디스 클러스터에선 서로 다른 해시슬롯에 속한 키에 대해서는 다중 키 커맨드를 못 쓴다.
user1:name, user2:name이 서로 다른 해시슬롯에 있고, 각 해시슬롯이 6001, 6003 마스터에 저장되있다.
클러스터는 키를 이용해 커맨드를 처리할 마스터로 클라의 연결을 리디렉션하기에 위와 같이 한 번에 2개 이상의 키에 접근해야하는 커맨드는 처리 불가하다.
이때는 해시태그란 기능을 쓰면된다.
레디스 클러스터는 데이터를 여러 서버에 분산 저장할 때, 키 전체를 해싱하여 저장 위치(Slot)를 결정한다. 하지만 키에 중괄호가 포함되어 있으면, 중괄호 안의 내용만 해싱한다.
user:{123}:profile
user:{123}:account
{user1000}.followers 해시되는 값: user1000
user{}id 해시되는 값: user{}id (중괄호가 비어있으면 전체 해싱)
user{{name}}id 해시되는 값: {name
user{name}{id} 해시되는 값: name (첫 번째 중괄호만 유효)
자동 재구성(페일오버, 복제본 마이그레이션)
레디스 Sentinel과 마찬가지로 클러스터에서도 복제와 자동 페일오버로 고가용성 확보가 가능하다.
다만 센티널에서는 고가용성을 위해 센티널 인스턴스가 추가로 필요했고, 별개의 센티널 인스턴스가 레디스 노드를 감시하는 구조였다면, 클러스터 구조에서는 데이터를 저장하는 일반 레디스 노드가 서로를 감시한다는 점에서 큰 차이가 있다.
- 센티널: 별개의 센티널 인스턴스가 레디스 노드 감시
- 클러스터: 레디스 노드끼리 감시 모든 노드들은 클러스터 버스를 통해 통신하며, 인스턴스에 문제가 생기면 자동으로 클러스터 구조를 재구성한다.
클러스터 사용 시 발생하는 재구성은 총 2가지.
- 마스터 노드에 장애 발생 시 복제본 노드를 마스터로 승격시키는 자동 페일오버
- 잉여 복제본 노드를 다른 마스터에 연결시키는 복제본 마이그레이션
자동 페일오버
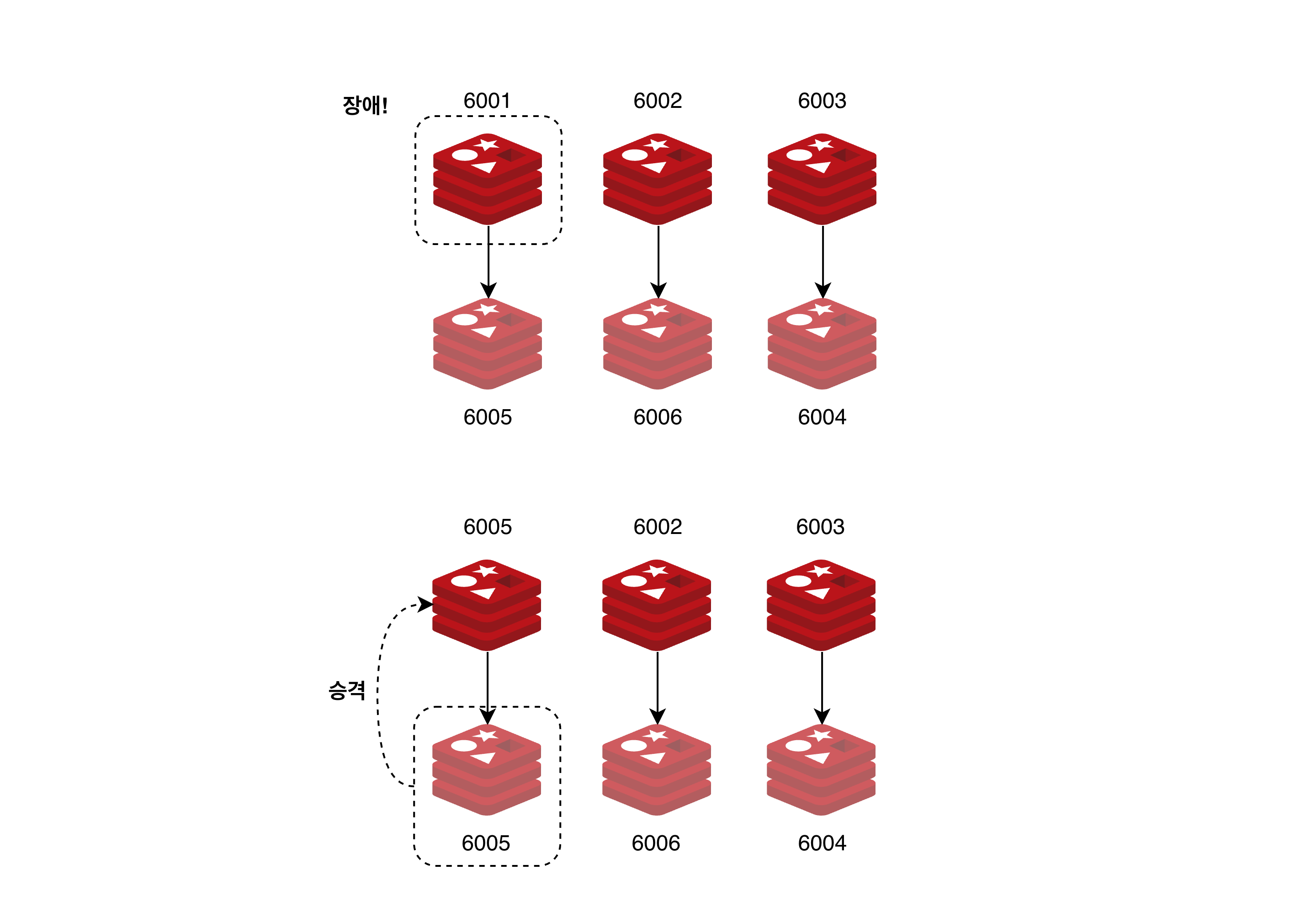
6001 마스터에 장애 시 6005 복제본은 다른 마스터 노드들에 페일오버를 시도해도 될지 투표를 요청한다. 투표 요청을 받은 다른 마스터 노드는 6001 마스터가 정상이 아니라고 판단할 경우 복제본에게 투표를 할 수 있으며, 과반수 이상의 마스터 노드에서 투표를 받은 6005번 복제본은 마스터로 승격된다.
만약, 이런 상황에서 6005 조차도 또 장애가 발생한다면?
다음 설정에 의해 클러스터 내의 마스터가 하나라도 정상이 아니면 전체 클러스터를 사용할 수 없게된다.
cluster-require-full-coverage yes
이 옵션은 기본 yes, 클러스터에서 일부 해시 슬롯이 사용 불가가 되면 즉 일부 노드만 다운 되어도 데이터 정합성을 위해 전체 상태가 fail 이 된다.
만약 가용성이 중요하며, 레디스 노드의 다운 타임을 줄이고 싶다면, 자동 복제본 마이그레이션이 가능하도록 아무 마스터 노드에 복제본을 하나 더 추가하는 것 고려해보자.
복제본 마이그레이션
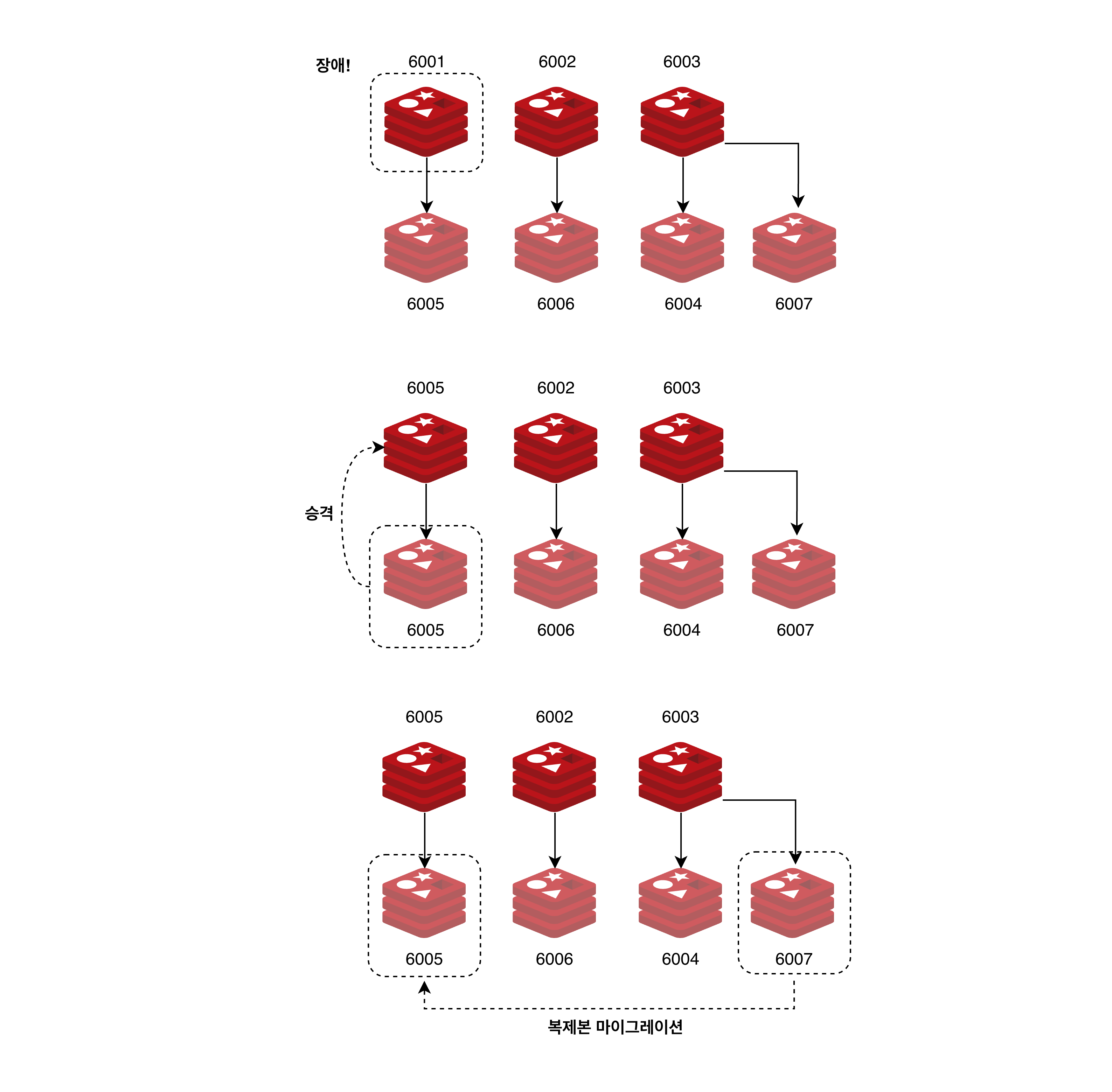
총 7개 노드 구성.6001, 6002 는 각각 1개 복제본, 6003은 2개의 복제본 가지고있다.
6001이 장애시 6005가 마스터로 승격된다. 승격되면 6005는 이제 복제본이 없으며 나머지 마스터들은 기존 복제본 그대로 들고있다.
이 상황에서 클러스터는 각 마스터에 연결된 복제본 노드의 불균형을 파악해 6003에 연결되어있는 2개의 복제본 중 하나의 복제본을 6005의 복제본이 되도록 이동시킨다. 이를 복제본 마이그레이션(replica migration) 이라 한다.
복제본 마이그레이션은
- 모든 마스터가 적어도 1개 이상의 복제본을 보장
- 이를 이용해 클러스터의 안정성을 향상시킴
물론 아무 복제본 노드가 마이그레이션되는 것은 아니고 다음과 같은 기준이 있다.
- 가장 많은 복제본이 있는 마스터의 복제본 중 하나가 선택
- FAIL이 아닌 복제본 중 노드 ID가 가장 작은 것 선택