[정리] Redis Sentinel
이 글은 개발자를 위한 레디스을 읽고 정리한 내용입니다.
서론
센티널은 레디스의 자체적인 HA(High Availability) 기능. 센티널은 장애 상황을 탐지해 자동으로 페일오버를 시켜준다.
애플리케이션이 센티널을 이용해 레디스에 연결하는 구조에서는 마스터에 장애가 발생하더라도 레디스로의 엔드포인트를 변경할 필요 없이 자동으로 페일오버가 완료되어 정상화된 마스터노드를 쓸 수 있다.
고가용성 기능 필요성
레디스는 인메모리 데이터베이스이므로 모든 데이터는 메모리에서 관리하며, 따로 백업을 하지 않았을 때 인스턴스 재시작시 모든 데이터는 유실된다.
만약 복제구성이라면 마스터에 장애 발생시 데이터는 복제본 노드에 남아있을 수 있다. 클라이언트가 마스터에 직접 연결된 상태였으면 다음 과정을 개발자가 직접 손을 써서 장애 상황을 복구 할 수 있을것이다.
- 복제본 노드에 직접 접속 후
REPLICA OF NO ONE커맨드로 읽기 전용 상태 해제 - 애플리케이션 코드에서 엔드포인트를 복제본의 IP로 변경
- 배포
운영 환경에서 별다른 고가용성 기능 없이 위와 같은 복제 구성으로만 레디스를 쓴다면 마스터 노드에서 발생한 장애 처리가 지연되 곧바로 서비스 기능의 장애로 이어질 수 있다.
혹은 레디스를 look aside 구성의 캐시로 사용하는 경우도 주의해야한다. look aside 구성에서는 애플리케이션이 캐시에 접근 못 할때 직접 MySQL 같은 원본 데이터를 읽어오려 시도한다. 레디스가 장애 발생시 원본 DB에 트래픽이 몰아쳐 운영중인 서비스에 영향을 미칠 수 있는 것.
센티널이란?
레디스의 자체 고가용성 기능.
센티널은 데이터를 저장하는 기존 레디스 인스턴스와는 다른 역할을 하는 별도의 프로그램이다. 센티널의 자동 페일오버 기능을 쓰면 마스터 인스턴스의 장애가 발생하더라도 알아서 레디스를 계속 사용할 수 있도록 동작해 레디스의 다운타임을 최소화 할 수 있다.
센티널 기능
- 모니터링: 마스터, 복제본 인스턴스의 상태를 실시간으로 확인
- 자동 페일오버: 마스터의 비정상 상태를 감지해 정상 상태의 복제본 중 하나를 마스터로 승격. 기존 마스터에 연결된 복제본은 새롭게 승격된 마스터에 연결됨
- 인스턴스 구성 정보 안내: 센티널은 클라이언트에게 현재 구성에서의 마스터 정보를 알려준다. 페일오버가 발생 시 변경된 마스터 정보를 재전달하기 때문에 페일오버가 발생하더라도 레디스의 엔드포인트 정보를 변경할 필요가 없다.
분산 시스템으로 동작하는 센티널
SPOF(Single Point of Failure) 는 하나의 서비스에 문제 발생시 전체 시스템이 영향을 받는 지점을 뜻한다. 복제와 자동 페일오버를 통해 고가용성을 확보하는 이유는 레디스가 SPOF가 되는 것을 방지하기 위함. 하지만 고가용성을 위해 도입하는 서비스가 SPOF 가 되버리면 사실 이는 도입할 필요가 없는 시스템이 되버린다!
센티널은 그 자체로 SPOF가 되는 것을 방지하기 위해 최소 3대 이상일때 정상 작동 되도록 설계됐으며, 하나의 센티널에 이상이 생겨도 다른 센티널이 계속해서 역할을 수행할 수 있게 되있다.
클라이언트는 센티널에 먼저 연결해 마스터의 정보를 받아온다. 만약 마스터, 복제 인스턴스가 정상이지만 센티널 인스턴스에 문제가 생겨 마스터 정보를 반환 못하게되면 클라이언트는 레디스로 새로운 커넥션은 못 맺게된다. 하지만 다행히 3대의 센티널이 있기에 하나의 센티널에 문제가 생겨도 클라는 다른 센티널에서 마스터의 정보를 정상적으로 받아올 수 있다.
센티널은 오탐을 줄이기 위해 쿼럼(quorum)이란 개념을 사용한다. 쿼럼은 마스터가 비정상 동작을 한다는 것에 동의해야 하는 센티널의 수. 이 쿼럼을 만족하는 경우 페일오버가 시작된다. 일반적으로 센티널 인스턴스가 3개일 때 쿼럼은 2로 설정하며, 이 경우 최소 2개 이상의 센티널 인스턴스가 마스터 비정상에 동의하면 페일오버 프로레스가 시작된다.
센티널은 쿼름을 이용한 과반수 선출 개념을 쓰기에 센티널 인스턴스는 3대 이상의 홀수로 구성하는게 좋다.
센티널 인스턴스 배치 방법
여기서는 센티널을 물리적으로 어떻게 배치하면 좋을지 알아본다. 기본적으로 센티널 인스턴스는 물리적으로 서로 영향받지 않는 서버에서 실행되는 것이 좋다. 마스터의 장애를 감지할 수 있어야 하기에 서로 다른 가용 영역에 배치하는 것이 일반적.
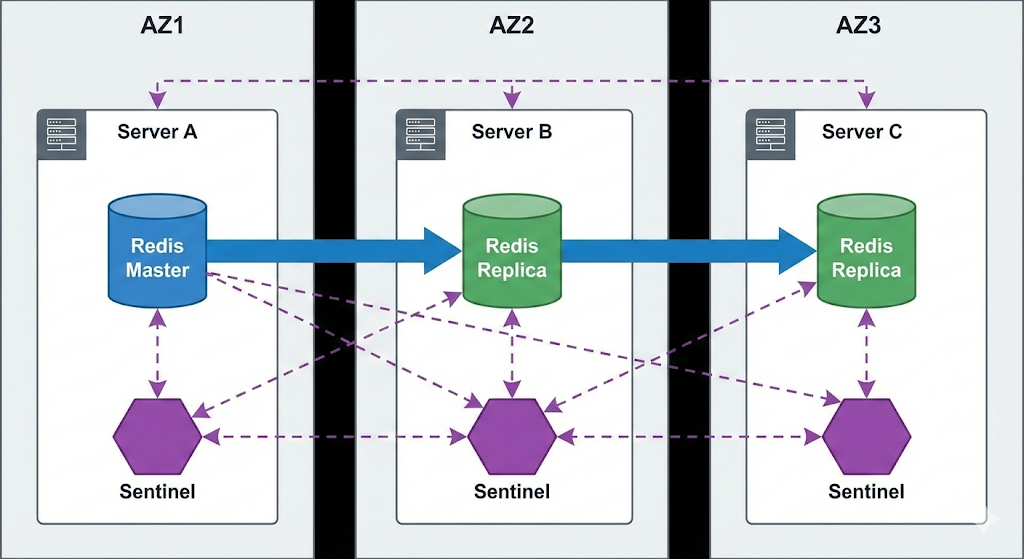
위 그림이 일반적인 배치 방법. 보통 하나의 서버에 레디스 프로세스와 센티널 프로세스를 동시에 실행시킨다.
만약 서버 A에 문제가 생겨 마스터 노드와 센티널에 접근 불가하게 되면 서버 B, C의 센티널 인스턴스가 마스터에 접근 불가한 상태라는 것을 동의한 뒤, 페일오버를 진행 시켜 다음과 같은 상태가 된다.
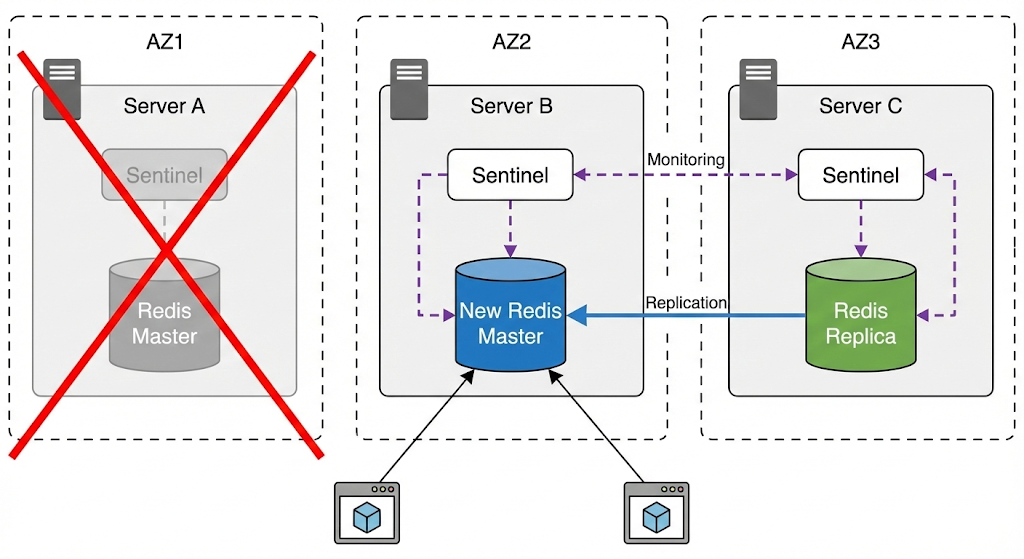
서버 B, C의 센티널 인스턴스는 새롭게 마스터가될 복제본을 선출한 뒤, 해당 복제본을 마스터로 승격시킨다. 이제 서버 C의 복제본 노드는 서버 B를 바라보도록 복제 연결을 변경한다.
기존 마스터를 바라보던 클라들은 모두 서버 B에서 새로 선출된 마스터로 연결되며, 레디스로 새롭게 들어오는 커넥션은 모드 마스터 IP 정보로 서버 B의 레디스 주소를 전달받는다.
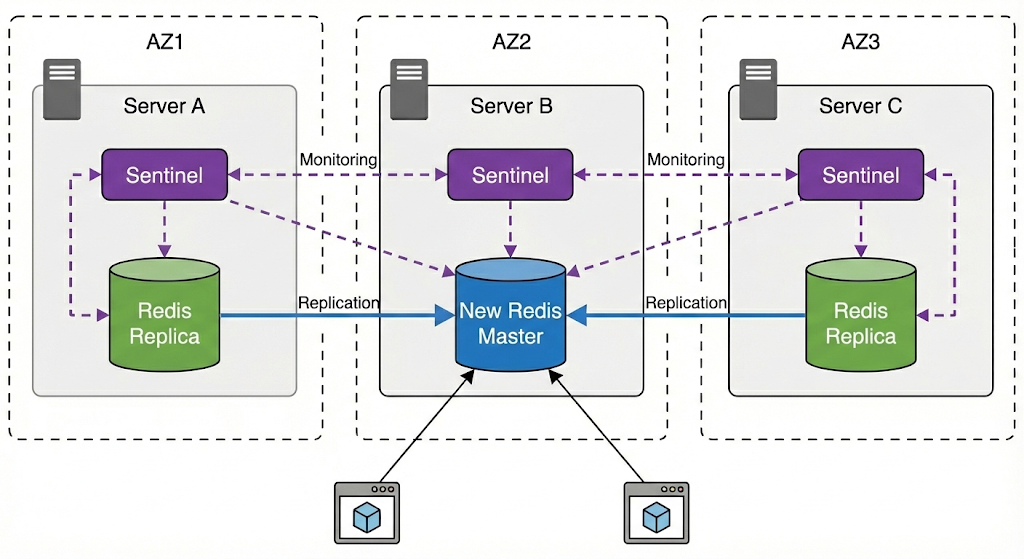
지금 상황에서 서버 A가 복구된다면 다음 그림같이 센티널 인스턴스들은 기존 마스터였던 서버 A의 레디스 인스턴스를 새롭게 마스터가된 서버 B의 복제본이 되도록 연결시킨다. 이 과정은 센티널 인스턴스의 판단으로 자동 구성되며 운영자 개입이 불필요하다.
서버 리소스에 여유가 있다면 앞선 예제와 같이 2개의 복제본을 가질수 있도록 하는게 가장 안정적. 하지만 경우에 따라 1개의 복제본으로도 충분한 서비스가 있을 수 있다. 이럴 경우 2대의 서버에는 레디스와 센티널 인스턴스를 동시에 실행시키고, 나머지 1대는 센티널 프로세스만 실행시키도록 배치할 수 있다. 이때 센티널만 실행되는 서버는 데이터 저장도, 클라이언트 요청도 받지 않는 서버라서 최저 사양 스펙이여도 무방하다.
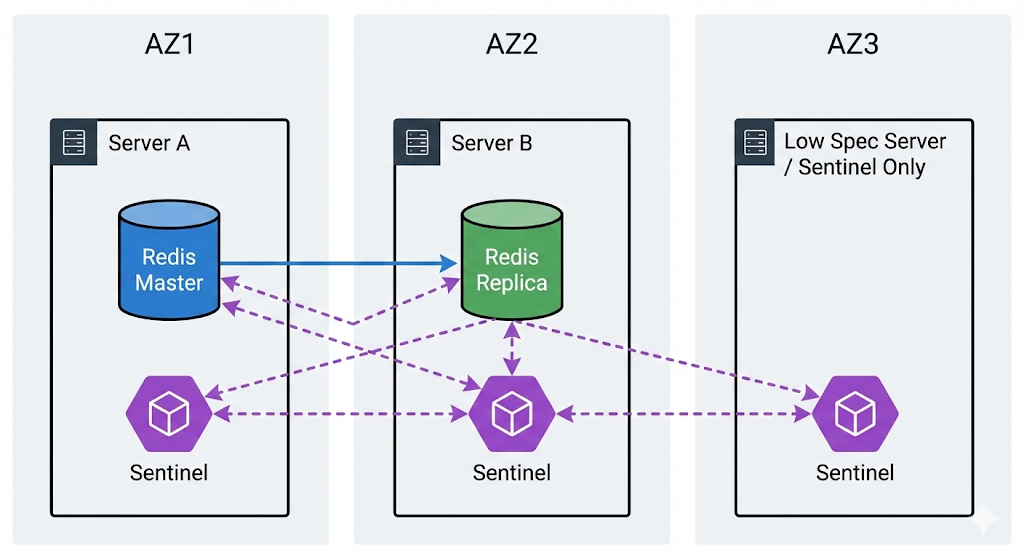 만약 여기서 A에 문제가 생기면 B, C에 센티널이 마스터 인스턴스에 접근이 불가한 상태인것을 동의한 뒤, 페일오버를 진행시켜 다음과 같은 상태가 된다.
만약 여기서 A에 문제가 생기면 B, C에 센티널이 마스터 인스턴스에 접근이 불가한 상태인것을 동의한 뒤, 페일오버를 진행시켜 다음과 같은 상태가 된다.
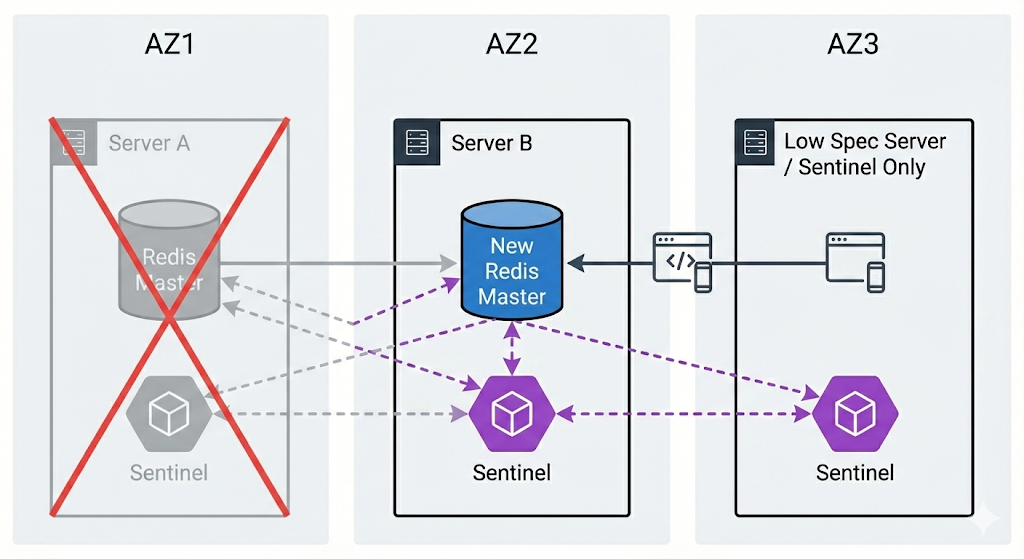
서버 C를 최저 사양으로 구축해 비용을 아끼면서도 마스터의 장애를 감지해 자동 페일오버를 수행할 수 있는 안정적인 구조다.
센티널 인스턴스 실행하기
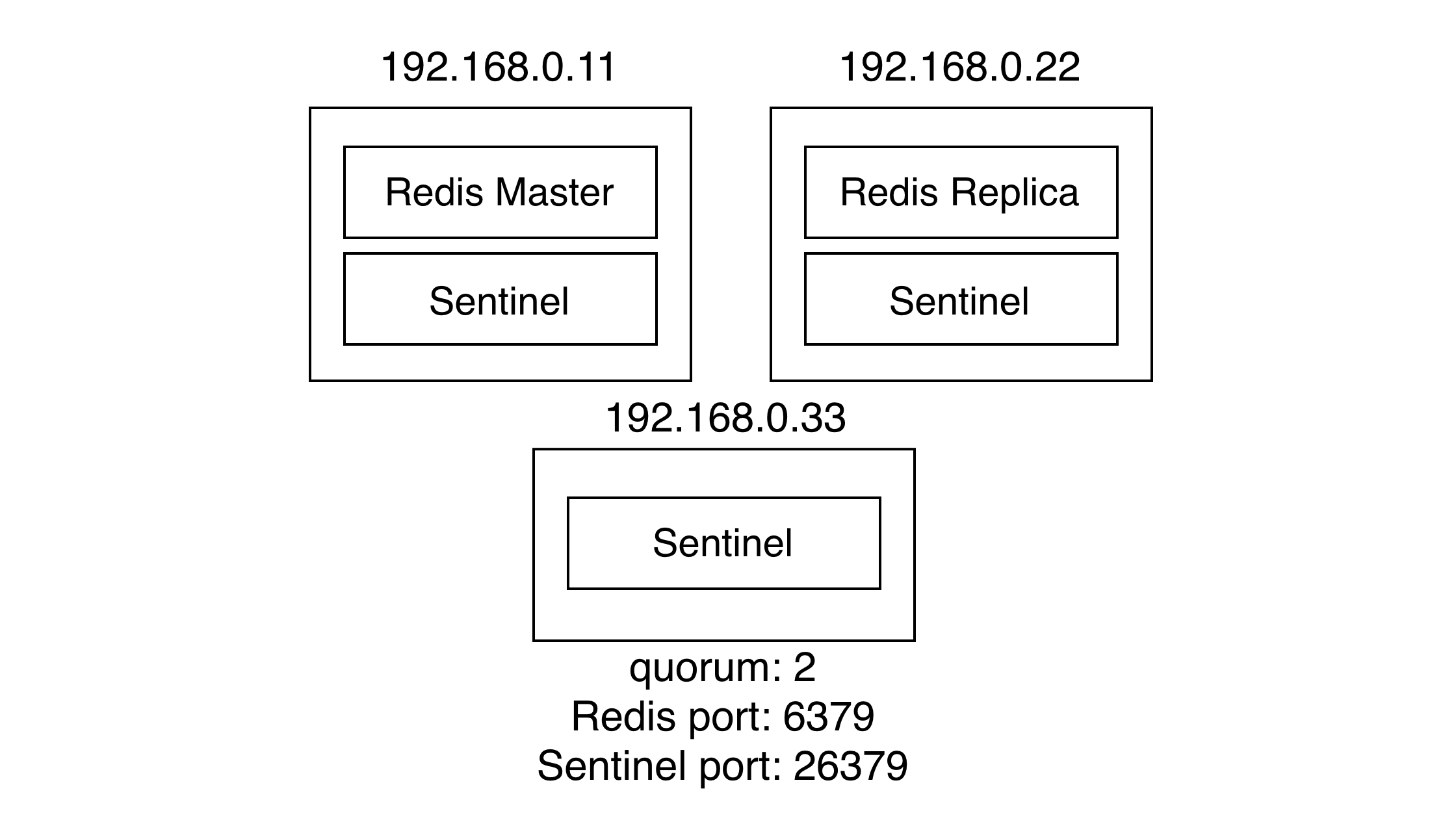 위와같이 인스턴스 배치가 되어있다. 모든 레디스 프로세스는 6379 포트, 센티널 프로세스는 26379 포트를 쓴다.
위와같이 인스턴스 배치가 되어있다. 모든 레디스 프로세스는 6379 포트, 센티널 프로세스는 26379 포트를 쓴다.
센티널 프로세스 실행
센티널 프로세스 실행 전 마스터와 복제본 노드 간 복제 연결이 된 상태로 만들자. 복제본 노드에서 다음 커맨드로 복제 연결을 시작할 수 있다.
REPLICAOF 192.168.0.11 6379
센티널 프로세스를 띄우기 위해서는 sentinel.conf란 별도의 구성파일이 필요하다. 이 파일에 다음 내용 추가한 뒤 센티널 프로세스를 시작하자.
port 26379
sentinel monitor master-test 192.168.0.11 6379 2포트는 당연히 센티널 프로세스가 실행될 포트. sentinel monitor는 모니터링할 마스터의 이름을 지정하고 쿼럼 값을 지정한다.
센티널은 마스터와 복제본 포함해 모든 레디스 프로세스를 모니터링하지만, 구성파일에는 복제본 정보를 직접 입력하지 않아도 된다. 센티널 프로세스가 시작하면 마스터에 연결된 복제본을 자동으로 찾아내는 과정을 거치기 때문.
이제 이 conf 로 센티널 인스턴스를 시작해보자. 센티널 인스턴스를 실행시킬 모든 서버에서 해당 파일 작성 뒤, 각각 인스턴스를 시작시켜야한다. 센티널은 다음 2개의 방법으로 실행 가능하다.
# redis-sentinel 이용
redis-sentinel /path/to/sentinel.conf
# redis-server 이용
redis-server /path/to/sentinel.conf --sentinel
2개 방법은 동일하게 동작한다.
모두 seontinel.conf이용해서 센티널 인스턴스를 시작한다.
지정된 위치에 해당 파일이 없거나 못 쓰는 데이터인경우 인스턴스는 시작되지 않는다.
레디스 프로세스에 접근할 때와 같이 레디스 커맨드라인 클라인 redis-cli을 통해 센티널 인스턴스에 직접 접근이 가능하다.
redis-cli -p 26379
이렇게 접속하면 센티널이 모니터링하고있는 마스터와 복제본 노드의 정보 그리고 복제본을 함께 모니터링하고 있는 다른 센티널 인스턴스에 대한 정보를 확인할 수 있다.
단, 레디스 인스턴스가 가지고 있는 데이터는 확인 불가하다.
SENTINEL master 커맨드를 쓰면 원하는 마스터의 IP, port, 연결된 복제본의 개수 등 다양한 정보를 확인 가능하다.
몇 가지 플래그에대한 설명하는데 이런건 진짜 운영을 하게되었을때 확인해보자.
SENTINEL replicas 커맨드를 쓰면 마스터에 연결된 복제본의 자세한 정보를 확인 가능하다.
SENTINEL sentinels 커맨드를 이용하면 마스터에 연결된 복제본의 자세한 정보를 확인할 수 있다.
SENTINEL ckquorum 을 쓰면 마스터를 바라보고 있는 센티널 인스턴스가 설정한 쿼럼 값보다 큰지 확인가능하다. 예를들어 정상 상태의 센티널이 3대, 쿼럼이 2일 경우 센티널 3대 모두 정상이라면 다음과 같은 값을 반환한다.
> SENTINEL ckquorum master-test
OK 3 usable Sentinels. Quorum and failover authorization can be reached
1대의 센티널에 문제가 생겨 정상적 센티널이 2대가 됬을 경우를 고려해보자. 정상적인 센티널 대수가 쿼럼 값인 2 이상이기에 전체 센티널 구성은 정상이라 판단할 수 있다. 이때는 다음과 같은 값을 반환한다.
> SENTINEL ckquorum master-test
OK 2 usable Sentinels. Quorum and failover authorization can be reached
이런 도중 1대가 더 장애가 발생한다면? 다음과 같다.
> SENTINEL ckquorum master-test
(error) NOQUORUM 1 usable Sentinels. Not enough available Sentinels to reach the specified quorum for this master. Not enough available Sentinels to reach the majority and authorize a failover
정상적인 센티널의 대수가 쿼럼보다 작기에 마스터 노드에 장애가 발생해도 투표가 불가해 페일오버를 자동으로 실행할 수 없다.
페일오버 테스트
두 가지 방법으로 페일오버를 발생시켜 테스트해 볼 수 있다.
커맨드를 이용(수동 페일오버)
SENTINEL FAILOVER <master name>
센티널에 직접 접속한 뒤 이 커맨드로 다른 센티널 동의 없이도 페일오버 바로 발생시킬 수 있다. 마스터의 상태가 정상이라도 이 커맨드를 쓰면 마스터와 복제본 간 롤 체인지가 발생한다.
센티널과 복제본 노드 간 네트워크 단절 이슈로 페일오버가 실패하지는 않는지, 센티널에 연결된 애플리케이션의 커넥션이 정상적으로 롤 체인지된 마스터에 연결되는 지 등 테스트가 가능하다.
마스터 동작을 중지시켜 페일오버 발생(자동 페일오버)
직접 마스터 노드에 장애를 발생시키는 방식.
다음과 같은 명령어로 레디스 프로세스를 셧다운 시킬 수 있다.
redis-cli -h <master-host> -p <master-port> shutdown
센티널은 주기적으로 마스터 노드에 PING 을 보내 응답이 정상적으로 돌아오는지 확인함으로 마스터 인스턴스의 상태를 확인한다. 이때 sentinel.conf에 지정한 down-after-milliseconds 시간 동안 마스터 응답이 안오면 마스터의 비정상이라 판단해 페일오버를 트리거한다. 해당 옵션의 기본값은 30,000 밀리초, 30초다.
센티널의 자동 페일오버 과정
앞서 센티널은 최소 3대의 노드가 함께 동작하는 분산 시스템이라 언급했다. 여러 센티널 노드가 레디스 인스턴스를 함께 감시하기에 레디스 상태에 대한 오탐을 줄일수 있다. 이렇게 여러 센티널이 마스터 인스턴스의 장애를 감지하고 페일오버시키는 과정에 대해 조금 더 자세히 알아보자.
마스터의 장애 상황 감지
센티널은 donw-after-milliseconds 파라미터에 지정된 값 이상동안 마스터에 보낸 PING 에 대해 유효한 응답 받지 못하면 마스터가 다운됐다 판단한다.
참고로 PING에 대한 유효한 응답은 +PONG, -LODADING, -MASTERDOWN 이며, 다른 응답이나 아예 못받는 경우 모두 유효하지 않다 판단한다.
sdown, odown 실패 상태로 전환
다음 그림과 같이 하나의 센티널 노드에사 레디스 마스터 인스턴스에 대한 응답을 늦게 받으면 그 센티널은 마스터의 상태를 우선 sdown으로 플래깅한다.
sdown이란 subjectly down 즉 주관적 다운상태를 의미한다.
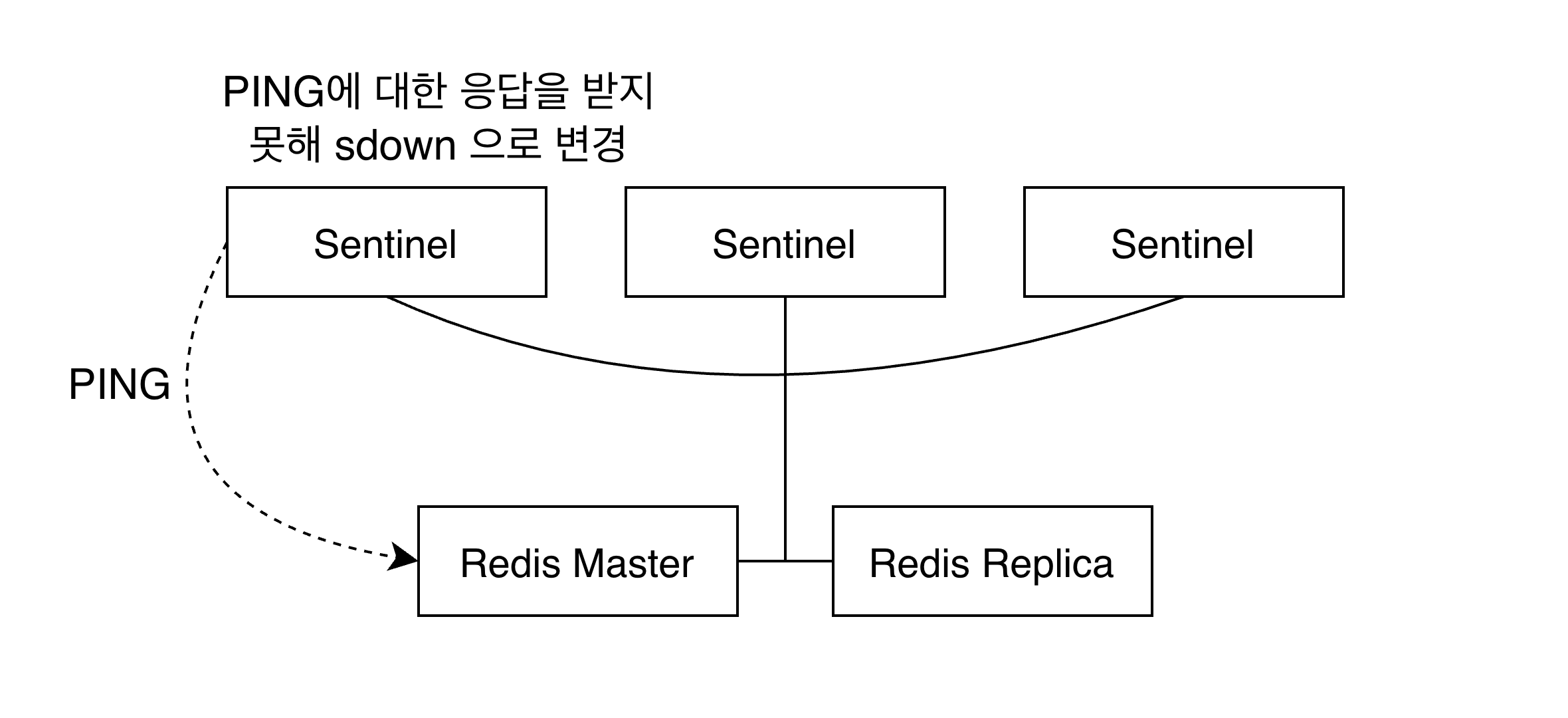
이후 센티널 노드는 다음과 같이 다른 센티널 노드들에
SENTINEL is-master-down-by-addr <master-ip> <master-port> <current-epoch> <*>
란 커맨드를 보내 다른 센티널에 장애 사실을 전파한다.
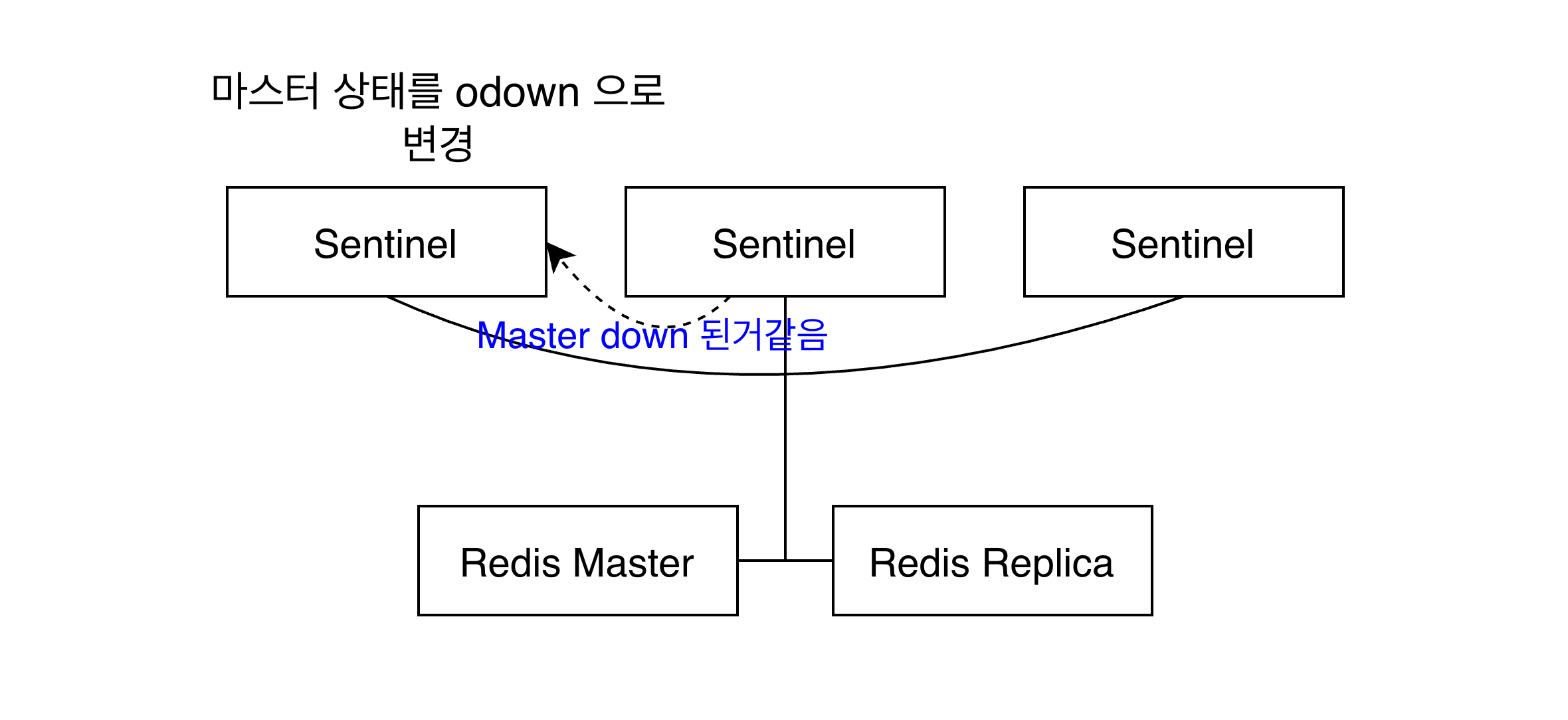
앞선 커맨드를 수신한 센티널들은 해당 마스터 서버의 장애를 인지했는지 여부를 응답한다. 자기 자신을 포함해 쿼럼 값 이상의 센티널 노드에서 마스터의 장애를 인지한다면 센티널 노드는 마스터의 상태를 odown으로 변경한다. odown은 objectily donw 객관적 다운 상태를 의미한다.
센티널은 마스터에 대해서만 odown 상태를 가진다. 센티널은 모든 레디스 노드를 모니터링하기에 복제본 노드에 장애 발생시 이를 인지한 뒤에 복제본 노드를 sdown으로 플래깅한다. 하지만 이 사실을 다른 센티널에 전파하거나해서 복제본을 odown 상태로 변경하지는 않는다. 장애 전파는 오직 마스터 노드에 관해서만 이뤄진다. 또한, sdown 상태인 복제본은 마스터로 승격될걸로 선택되지 않게된다.
에포크 증가
처음으로 마스터 노드를 odown으로 인지한 센티널 노드가 페일오버 과정을 시작한다. 센티널은 페일오버를 시작하기 전 우선 에포크값을 하나 증가시킨다.
센티널은 에포크란 개념을 이용해 각 마스터에서 발생한 페일오버의 버전을 관리한다. 에포크는 증가하는 값으로, 처음으로 페일오버가 일어날 때의 에포크 값은 1이 된다. 새로운 페일오버 발생마다 에포크는 하나씩 증가하고, 동일한 에포크 값을 이용해 페일오버 과정이 진행되는 동안 모든 센티널 노드가 같은작업을 시도하고있다는걸 보장할 수 있다.
센티널 리더 선출
에포크를 증가시킨 센티널은 그림과 같이 다른 센티널 노드에게 센티널 리덜르 선출하기위해 투표하라는 메시지를 보낸다. 이때 증가시킨 에포크를 함께 전달하는데 해당 메시지를 받은 다른 센티널 노드가 현재 자기 에포크보다 클 경우 자신의 에포크를 증가시킨되, 센티널 리더에게 투표하겠다는 응답 보낸다.
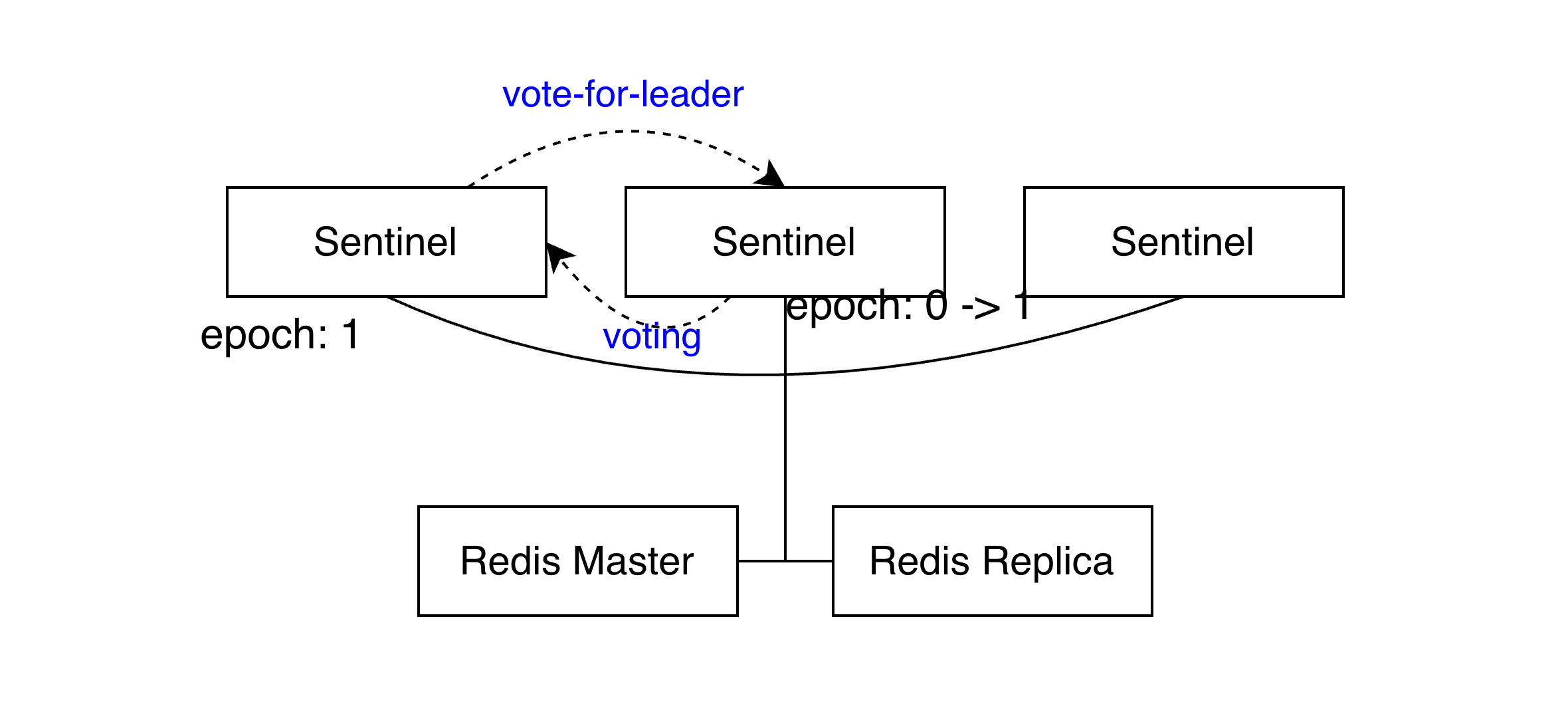
만약 센티널 노드가 투표를 요구받았을 때 전달 받은 에포크 값이 자기와 동일할 때는 이미 리더로 선출한 센티널의 id를 응답한다. 하나의 에포크에서 센티널은 하나의 센티널에투표할 수 있다. 변경은 불가함.
과반수와 쿼럼 센티널이 마스터를 sdonw -> odown으로 변경 위해선 쿼럼 값 이상의 센티널 동의가 필요하다. 하지만 페일오버를 하려면 센티널 리더를 선출할 때 쿼럼 값이 아닌 실제 센티널 개수 중 과반수 이상의 센티널 동의를 얻어야 리더가 된다. 쿼럼 값 보다 큰 센티널이 동의했을 경우에도 그 수가 과반보다 작다면 페일오버는 발생않는다.
예를들어 센티런 5개, 쿼럼 2일때 odown이 되어 페일오버가 트리거 될 수는 있으나, 2개의 센티널만 동의한 경우 센티널 리더를 선출 불가해 페일오버가 발생 않는다.
복제본 선정 후 마스터로 승격
과반수 이상의 센티널이 페일오버에 동의했다면 리더 센티널은 페일오버를 시도하기 위해 마스터가 될 수 있는 적당한 복제본을 선정한다. 이때 마스터로부터 오랜기간 연결이 끊겼던 복제본은 자경이 없다. 자격이 있다면 다음의 우선순위로 선출된다.
redis.conf파일에 명시된replica-priority가 낮은 복제본- 마스터로부터 더 많은 데이터를 수신한 복제본(master_repl_오프셋)
- 2번 조건까지 동일하다면,
runID가 사전순으로 작은 복제본 선정된 복제본은slaveof no one커맨드를 수행해, 기존 마스터로부터의 복제를 끊는다.
복제 연결 변경
기존 마스터에 연결되어있던 다른 복제본들이 새로 승격된 마스터의 복제된이 될 수 있도록 복제본마다 replicaof new-ip new-port 커맨드를 수행해 복제 연결을 변경한다. 복제 그룹의 모든 센티널 노드에서도 레디스 구성 정보를 병경한다.
장애 조치 완료
모든 과정이 완료되고 센티널은 새로운 마스터를 모니터링한다.
스플릿 브레인 현상
Split Brain 이란 네트워크 파티션 이슈(클러스터 이슈로 봐도 될 듯)로 인해 분산 환경의 데이터 저장소가 끊어지고, 그 단절된 두 부분이 각각을 정상적인 서비스라 인식하는 현상.
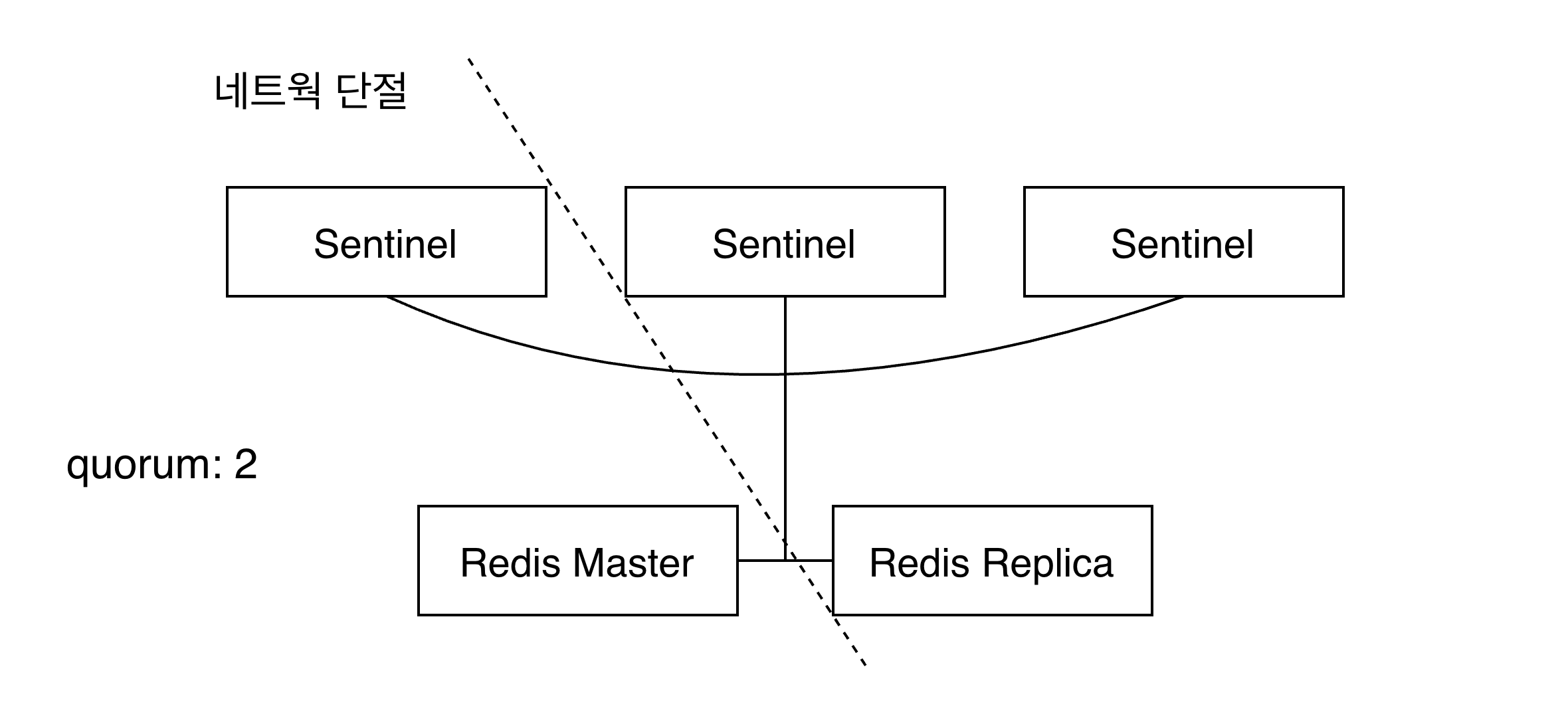
위 그림과 같이 네트워크 단절이 발생하면 스플릿 브레인 현상이 발생 할 수 있다. 마스터와 센티널 A 그리고 복제본 노드, 센티널 B, C 간 네트워크 단절이 일어난 경우다.
단절이 길어지면 센티널 B, C는 마스터 노드로의 접근이 정상적이지 않다는 것을 감지한 뒤, 복제본 노드를 마스터로 승격 시킨다. 과반수 이상의 센티널이 같은 네트워크 파티션에 있기에 가능한 현상. 만약 마스터 인스턴스에는 장애가 발생하지 않았으며, 단지 노드간 네트워크 단절이 발생한 경우라면 2개의 마스터가 생기는 스플릿 브레인 현상이 발생한다.
클라이언트는 레디스에 연결할 때 센티널에 마스터 주소를 질의한 뒤 곧바로 마스터에 직접 연결된다. 단절된 상태에서 클라이언트가 우측의 센티널 C에 마스터를 질의하면, 결론적으로 우측의 마스터에 연결되게 된다.
만약 네트워크 단절이 복구된다면? 기존 마스터는 센티널 B, C에 의해 새롭게 승격된 마스터의 복제본으로 연결된다.
이 예에서는 옛날 마스터가 신규 마스터의 복제본으로 하향당한다.
복제본으로 연결되는 과정에서 복제본 노드의 데이터는 모두 삭제되기에 기존 마스터가 네트워크 단절 동안 처리했던 모든 데이터는 유실된다.