Challenge: 메모리 제약과 비정형 데이터 관리#
MY CODING TEST 프로젝트에서 소스 코드와 메모 같은 비정형 데이터를 MySQL에 직접 저장하려 했습니다. 그러나 AWS 1GB 메모리 인스턴스에서 스프링
서버를 운영하며 JVM의 기본 최대 힙 크기가 240MB로 제한된다는 점에서 다음과 같은 우려가 생겼습니다:
- 메모리 부담: 클라이언트 요청이 스프링 서버로 전달되면 데이터 크기만큼 JVM 힙 메모리에 로드됨
- 비정형 데이터의 불확실성: 문제 번호, 타이틀, 채점 결과 등 정형 데이터는 크기가 작고 예측 가능한 반면에 소스 코드와 메모는 사용자에 따라 크기가 천차만별이며, 복잡한 문제 풀이 시 대용량 데이터 발생
가능
- 성능 저하 위험: 240MB 힙 크기 제한 하에서 대용량 요청이 동시에 발생하면 GC(가비지 컬렉션)가 빈번해지고, 스프링 앱 성능이 저하될 가능성
1GB 시스템에서의 JVM default Heap Memory 확인
1
2
3
4
| ubuntu@ip-**:~$ java -XX:+PrintFlagsFinal -version | grep -iE 'HeapSize|PermSize|ThreadStackSize'
... 생략 ...
size_t MaxHeapSize = 241172480 {product} {ergonomic}
... 생략 ...
|
Action: AWS S3를 활용한 분산 스토리지 도입#
DynamoDB 검토와 배제#
DynamoDB 고려 이유
- 무료로 15GB의 용량을 제공
- Key-Value 방식이라 사용하기 매우 쉬움
- AWS SDK가 잘되어 있어 IAM, Gradle 설정만 해주면 쉬운 구현이 가능
DynamoDB 배제 이유
- 무료 15GB와 Key-Value 방식은 매력적이지만, 용량 기반 과금의 불확실성과 예상치 못한 비용 우려로 배제
- 소스 코드와 메모 데이터는 높은 읽기/쓰기 성능이 필수적인 데이터가 아니라는 판단
- 가장 중요한 점은, DynamoDB를 사용하더라도 결국 스프링 애플리케이션이 데이터를 로드해야 한다는 점. 저장소 변경을 통한 속도 향상은 기대할 수 있지만, 근본적인 메모리 절약과는 무관
S3 선택: 비용 효율성과 메모리 절약#
이후,비용 효율성과메모리 절약을 핵심 목표로 AWS Simple Storage Service(S3)를 도입하기로 결정했습니다.
- 메모리 절약
- AWS에서 제공하는 Signed URL 기능을 활용하여 클라이언트가 S3에 직접 데이터를 업로드/다운로드할 수 있도록 설계하여 스프링 서버의 메모리 부담을 최소화 가능
- 비용 효율적인 과금 구조
- DynamoDB와 비교하여 예측 가능한 요청 기반 과금 체계를 제공
Signed URL을 활용한 직접 업로드/다운로드 방식#
S3의 Signed URL 기능을 활용하여 다음과 같은 이점을 얻을 수 있었습니다.
- 서버 부담 감소
- 클라이언트가 S3와 직접 통신하여 대용량 텍스트 데이터를 처리하므로, 스프링 서버는 데이터 전송 및 저장 과정에서 발생하는 메모리 오버헤드를 제거할 수 있습니다.
- 보안 강화
- Signed URL은 특정 시간 동안만 유효하므로, 데이터에 대한 무단 접근을 방지할 수 있습니다.
설계 및 구현#
spring-cloud-aws-starter의 S3Template을 활용하여 Signed URL 생성 로직을 구현했습니다.
- Signed URL 생성 과정
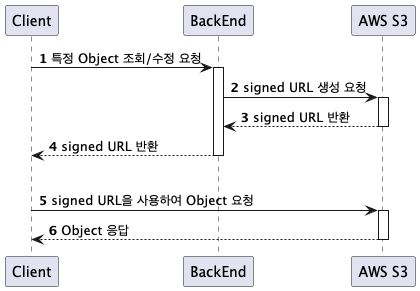
- 클라이언트는 스프링 서버에 Signed URL 생성을 요청합니다.
- 스프링 서버는 AWS S3에 Signed URL 생성을 요청하고, 유효 기간이 설정된 URL을 응답받습니다.
- 스프링 서버는 클라이언트에게 Signed URL을 전달합니다.
- 클라이언트는 전달받은 Signed URL을 사용하여 S3에 데이터를 업로드/다운로드합니다.
다음 그림은 Signed URL 생성하는 과정에대한 시퀀스 다이어그램
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
@Service
public class S3Service {
private final S3Template s3Template;
@Value("${aws.s3.bucketName}")
private String bucketName;
@Value("${aws.s3.urlExpirationSeconds}")
private int urlExpirationSeconds;
public S3Service(S3Template s3Template) {
this.s3Template = s3Template;
}
public String getCodeReadUrl(String submissionId, Long userId) {
String key = userId + "/codes/" + submissionId + ".txt";
return s3Template.createSignedGetURL(bucketName, key, Duration.ofSeconds(urlExpirationSeconds)).toString();
}
public String getCodeUpdateUrl(String submissionId, Long userId) {
String key = userId + "/codes/" + submissionId + ".txt";
return s3Template.createSignedPutURL(bucketName, key, Duration.ofSeconds(urlExpirationSeconds)).toString();
}
public String getMemoReadUrl(String reviewId, Long userId) {
String key = userId + "/memos/" + reviewId + ".txt";
if (s3Template.objectExists(bucketName, key)) {
return s3Template.createSignedGetURL(bucketName, key, Duration.ofSeconds(urlExpirationSeconds)).toString();
}
return "noMemo";
}
public String getMemoUpdateUrl(String reviewId, Long userId) {
String key = userId + "/memos/" + reviewId + ".txt";
return s3Template.createSignedPutURL(bucketName, key, Duration.ofSeconds(urlExpirationSeconds)).toString();
}
public void deleteCodes(List<String> submissionIdList, Long userId) {
for (String submissionId : submissionIdList) {
String key = userId + "/codes/" + submissionId + ".txt";
s3Template.deleteObject(bucketName, key);
}
}
public void deleteMemo(String reviewId, Long userId) {
String key = userId + "/memos/" + reviewId + ".txt";
s3Template.deleteObject(bucketName, key);
}
}
|
Result#
S3와 클라이언트 간의 직접 통신에 의해 스프링은 비정형 데이터 전송 및 저장 과정에서 발생하는 메모리 로드를 절약할 수 있게 되었습니다.
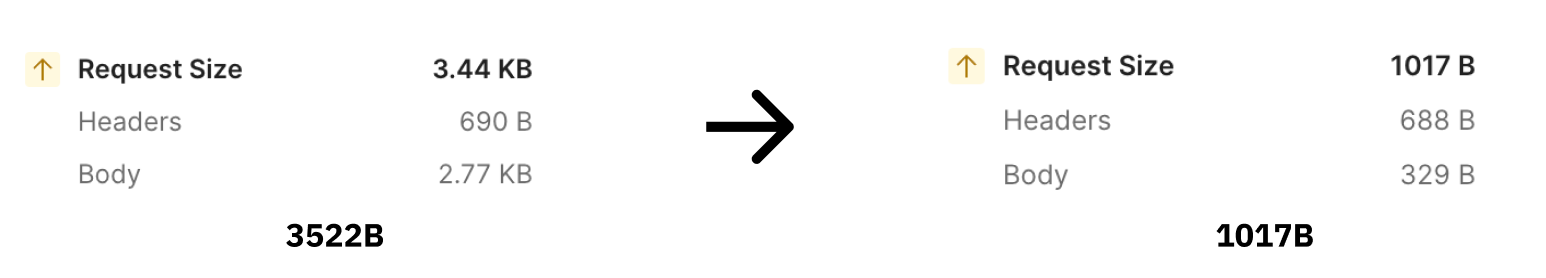
- 개선된 특정 API 요청 1건당 Request Size 절약량
- 3522B -> 1017B (약 71.1% 감소)
감소된 Request Size만큼 메모리 로드에 대한 부담이 경감되었습니다.