MVCC: Undo Log와 Read View로 데이터의 시점 관리하기
서론
최근 "MVCC를 활용해서 실제로 MySQL에서는 어떻게 데이터가 조회될까요?"같은 질문을 받았고 당황했던 경험이 있다.
MVCC를 InnoDB의 REPEATABLE READ 격리 수준에서 Phantom Read를 방지를위한 장치로만 이해해 왔다.
하지만 정작 MVCC가 Undo Log와 Read View(스냅샷)를 통해 어떻게 물리적으로 일관된 스냅샷을 생성하고 관리하는지, 그 구체적인 동작 원리에 대해서는 하나도 모르고있었다.
몰랐다면 공부하면되는것 아니겠나? 이번 글에서는 MVCC로 어떻게 DBMS가 동작하는지에관해 알아보려한다.
RealMySQL 책과 웹 서치, 생성형 AI 등에서 나오는 자료를 기반으로 저만의 언어로 재기술 한 글입니다.
MVCC
mvcc의 가장 큰 목적은 잠금을 사용하지 않는 일관된 읽기의 제공이다.
InnoDB같은 경우는 이를 언두 로그(Undo log)를 이용해서 구현한다. 이름에서 알 수 있듯이 Multi Version 즉 하나의 레코드에 대해 여러 번전이 동시에 관리된다는 의미다.
과정 정리 1: 데이터 변경 시
Isolation Level이 READ_COMMITED인 MySQL의 데이터 변경에 관한 과정이다.
데이터가 INSERT 되면 데이터베이스 상태는 다음과 같다.
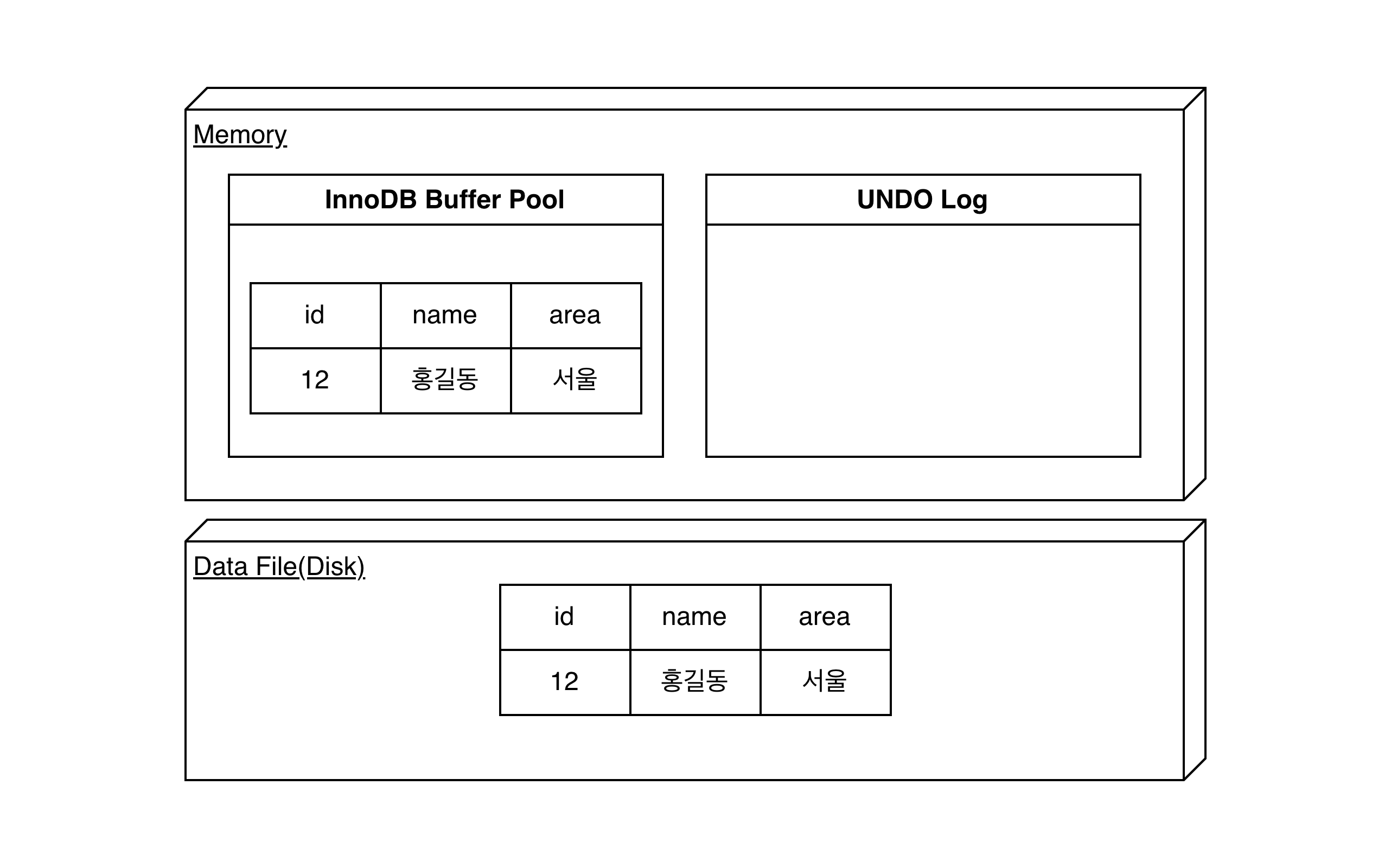
이제 업데이트(UPDATE member SET ...)를 시도해면 다음과 같이 동작한다.
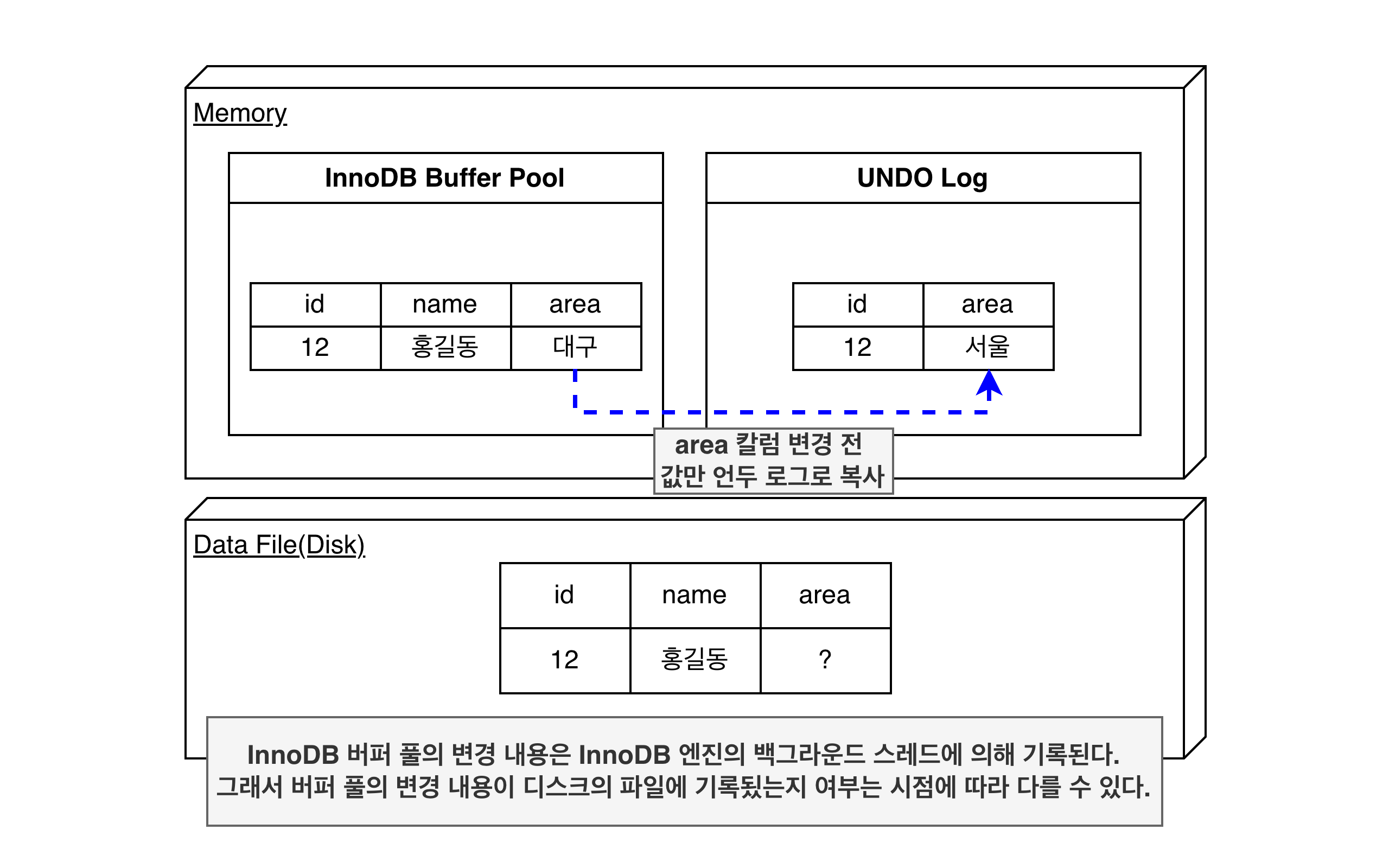
UPDATE가 실행되면 커밋 실행 여부와 무관히 InnoDB의 버퍼풀은 새로운 값인 '대구'로 업데이트 된다. 그리고 디스크의 데이터 파일에는 체크포인트나 InnoDB의 Write 스레드에의해 새로운 값이 업데이트 될수도 아닐수도 있다. (InnoDB는 ACID를 보장하기에 일반적으로 버퍼 풀과 데이터 파일을 동일 상태라 가정해도 무방)
이때 COMMIT or ROLLBACK이 아직 안되었으면 다른 사용자가 다음과 같은 쿼리SELECT * FROM member WHERE id = 12;로 작업 중인 레코드를 조회하면 어디에 위치한 데이터를 조회할까?
답은 MySQL의 시스템 변수인 transaction_isolation에 설정된 격리 수준에 의존한다는 것이다.
READ_UNCOMMITED인 경우는 버퍼 풀이 현재 가지고 있는 변경된 데이터를 읽어 반환한다.
커밋되었든 아니든 변경된 상태의 데이터를 반환해주는 것이다.
반면 READ_COMMITED, REPEATABLE_READ, SERIALIZABLE 같은건 아직 커밋되지 않았기에 버퍼 풀이나 데이터 파일에 있는 내용 대신 변경되기 이전의 내용을 보관하고 있는 언두 영역의 데이터를 반환한다.
이런 과정을 "DMBS에서는 MVCC라 표현"한다.
READ_COMMITED 부터는 Read View 또는 Snapshot 이라 불리는 구조체를 하나 만든다. 이 구조체는 해당 스냅샷 만든 tx_id, 그 당시 활동 중 이던 tx_id 모음, max tx id, min tx id 등이 존재한다. 이 값들로 버퍼 풀의 데이터만 보고 끝낼지 데이터에 있는 undo log pointer를 써서 undo 로그를 탐색할지 판단하게 된다.(가시성을 판단한다고도 말할 수 있음)
즉, 하나의 레코드(id = 12)에 대해 2개의 버전이 유지되고, 필요에 따라 어느 데이터가 보여지는이 상황에 따라 달라지는 구조인것.
이 버전은 무한히 많아 질 수 있다. 트랜잭션이 길어지면 언두 로그에서 관리하는 예전 데이터가 삭제되지 못하고 오래 보관되야하니 언두 영역에 저장되는 시스템 테이블스페이스 공간이 늘어나는 상황이 발생할 수도 있다.
지금까지 UPDATE 시 버퍼 풀은 즉시 새로운 데이터로 변경되고 기존 데이터는 언두영역으로 복사되는 과정을 살펴봤다. 여기서 COMMIT 아닌 ROLLBACK을 하면 InnoDB는 언두 영역에 있는 백업 데이터를 InnoDB 버퍼 풀로 복구하고, 언두 영역의 내용을 삭제한다. 커밋이 되었다고 언두 영역에 있던 백업 데이터가 바로 삭제되는건 아니고, 이 언두 영역을 필요로하는 트랜잭션이 없을때 비로소 삭제된다.
InnoDB 버퍼 풀의 변경 내용은 InnoDB 엔진의 백그라운드 스레드에 의해 기록된다. 그래서 버퍼 풀의 변경 내용이 디스크의 파일에 기록됬는지 여부는 시점에 따라 다를 수 있다.
과정 정리 2: 데이터 읽기 시
InnoDB 엔진은 MVCC를 이용해서 잠금을 걸지 않고 읽기 작업((Non-Locking Consistent Read)을 수행한다. 잠금이 없으니 읽기 작업같은 경우는 다른 트랜잭션에 영향 받지않고 읽기 작업이 가능하다.
격리 수준이 SERIALIZABLE이 아닌 READ_UNCOMMITED, READ_COMMITED, REPEATABLE_READ인 경우 INSERT와 연결되지 않는 순수한 읽기(SELECT)는 다른 트랜잭션의 변경 작업과 무관히 항상 바로 조회된다.
락이랑 무관히 조회하는 것이다.
다음 그림처럼 특정 사용자가 레코드를 변경하고 아직 커밋을 안했어도 이 UPDATE 트랜잭션은 타 트랜잭션의 SELECT를 방해하지 않는다. 이를 'Non-Locking Consistent Read'라 지칭하며, InnoDB에서는 변경되기 전 데이터를 읽기 위해 언두 로그를 사용한다. 또한 위에 말한것 처럼 이 언두 로그를 읽을지 말지는 Read View(Snapshot)을 기준으로 판단한다. Version을 탐색하는 과정.
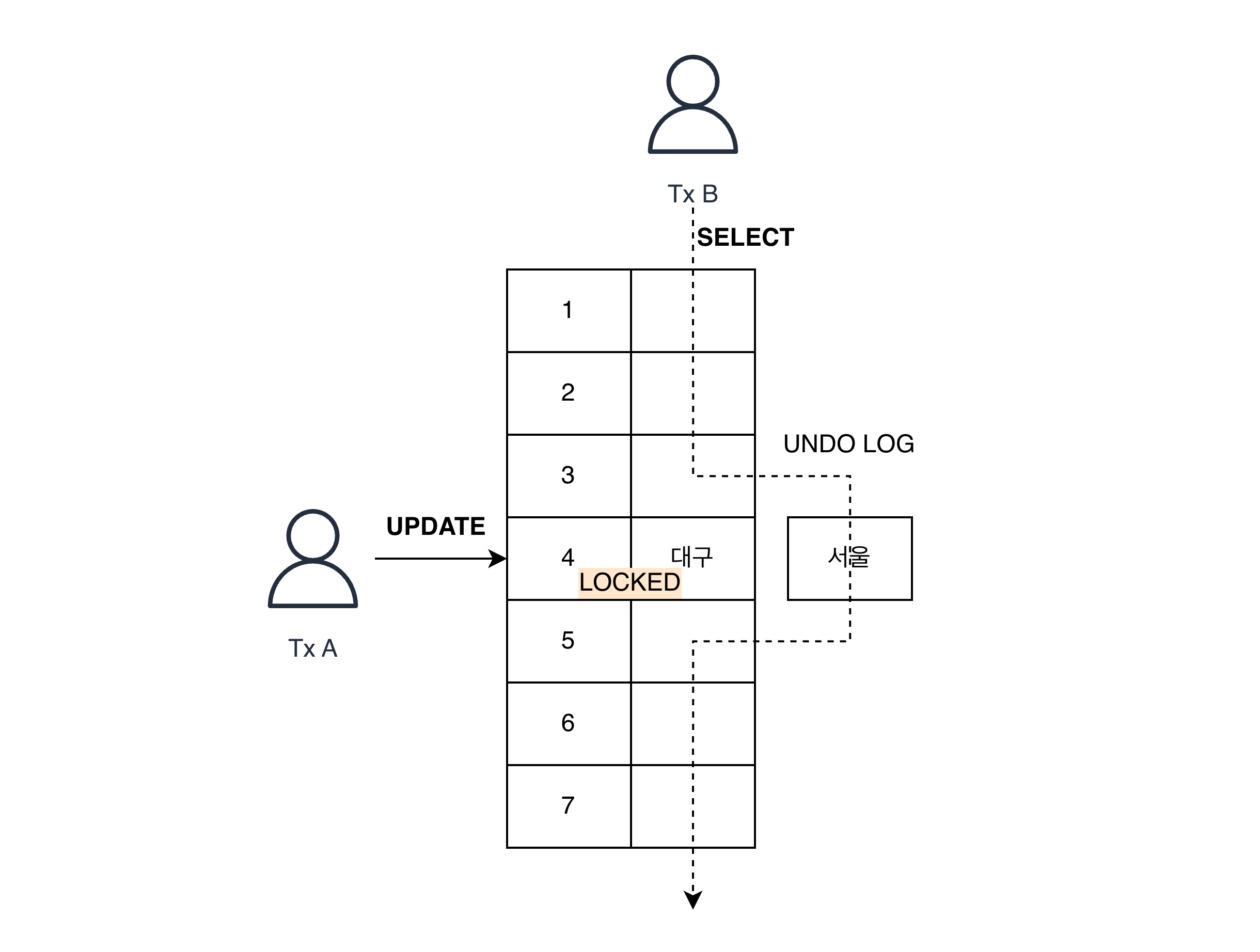
읽기 과정 정리
- 데이터 변경: 트랜잭션 B가 데이터를 수정하면, InnoDB는 기존 데이터를 버리지 않고 언두 로그 영역에 보관한다.
- 읽기 요청: 트랜잭션 A가 SELECT를 하면, 시스템은 트랜잭션 A의 **Read View(Snapshot)**를 확인한다.
- 버전 찾기: 시스템은 언두 로그를 타고 올라가며 "이 데이터는 내(트랜잭션 A)가 시작된 이후에 바뀐 거네? 그럼 이전 버전을 보여줘야지"라고 판단한다.
- 재구성: 언두 로그에 저장된 정보를 바탕으로 트랜잭션 A에게만 과거 시점의 데이터를 보여준다.
언두 로그 vs Read View(Snapshot)
- 언두 로그: 데이터가 변경될 때마다 기록되는 '변경 전 데이터의 복사본'
- Read View(Snapshot): 특정 트랜잭션이 시작된 시점에 '어떤 버전의 데이터를 읽어야 할지'를 결정하는 기준표
오랜 시간 활성화 상태인 트랜잭션으로 인해 DBMS가 느려지거나하는 이슈가 발생할수 있는데 원인이 일관된 읽기를 지원하기 위한 언두 로그가 삭제되지 못하고 쌓여서 일 수 있다. 따라서 트랜잭션이 시작되었다면 가능한 빨리 커밋이든 롤백이든 하는것이 좋은 것.
스냅샷은
REPEATABLE READ의 경우는 트랜잭션 시작 시 한번 생성되고,READ COMMITED는 트랜잭션 동안 SELECT가 발생 시 마다 생성된다. 이러니REPEATABLE READ에서 트랜잭션이 길어질 경우 UNDO LOG가 비대해져 저장공간 부족이나 UNDO LOG 탐색 시간이 길어질 수 있는 것이다. 격리수준이 높아진 만큼 성능 저하가 발생하는 한 예로 보인다.
REPEATABLE READ의 MVCC 더 자세히
REPEATABLE READ는 MVCC를 위해 언두 영역에 백업된 이전 데이터를 이용해 동일 트랜잭션 내에서는 동일한 결과를 보장한다.
READ COMMITED도 MVCC로 COMMIT전 데이터를 보여주느데 이 두개의 차이는 언두 영역에 백업된 레코드의 여러 버전 가운데 몇 번째 이전 버전까지 찾아 들어가냐에 대한 차이가 있다.
모든 InnoDB 트랜잭션은 고유한 번호(순차적으로 증가)를 가지며, 언두 영역에 백업된 모든 레코드에는 변경을 발생시킨 트랜잭션 번호가 포함되있다. 그리고 언두 영역의 데이터는 엔진이 불필요하다 여기는 시점에 주기적으로 삭제된다.
REPEATABLE READ 수준에서는 MVCC 보장위해 실행중 트랜잭션 가운데 가장 오래된 트랜잭션 번호를 가진 언두 영역의 데이터는 삭제가 불가하다.
그렇다고 가장 오래된 트랜잭션 이전의 트랜잭션에 의해 변경된 언두 데이터가 모두 필요한건 아니다.
정확히는 특정 트랜잭션 번호 구간 내에서 백업된 언두 데이터가 보존되야한다.
REPEATABLE READ가 작동하는 방식
작동하는 방식을 알아보자. employees테이블을 번호가 6인 트랜잭션에 의해 INSERT 되었다 가정한다.
밑의 자료는 사용자 A가 emp_no가 500000인 사원 이름 변경하는 과정에서 B가 emp_no=500000인 사원 SELECT할 때 어떤 과정이 일어나는지 보여준다.
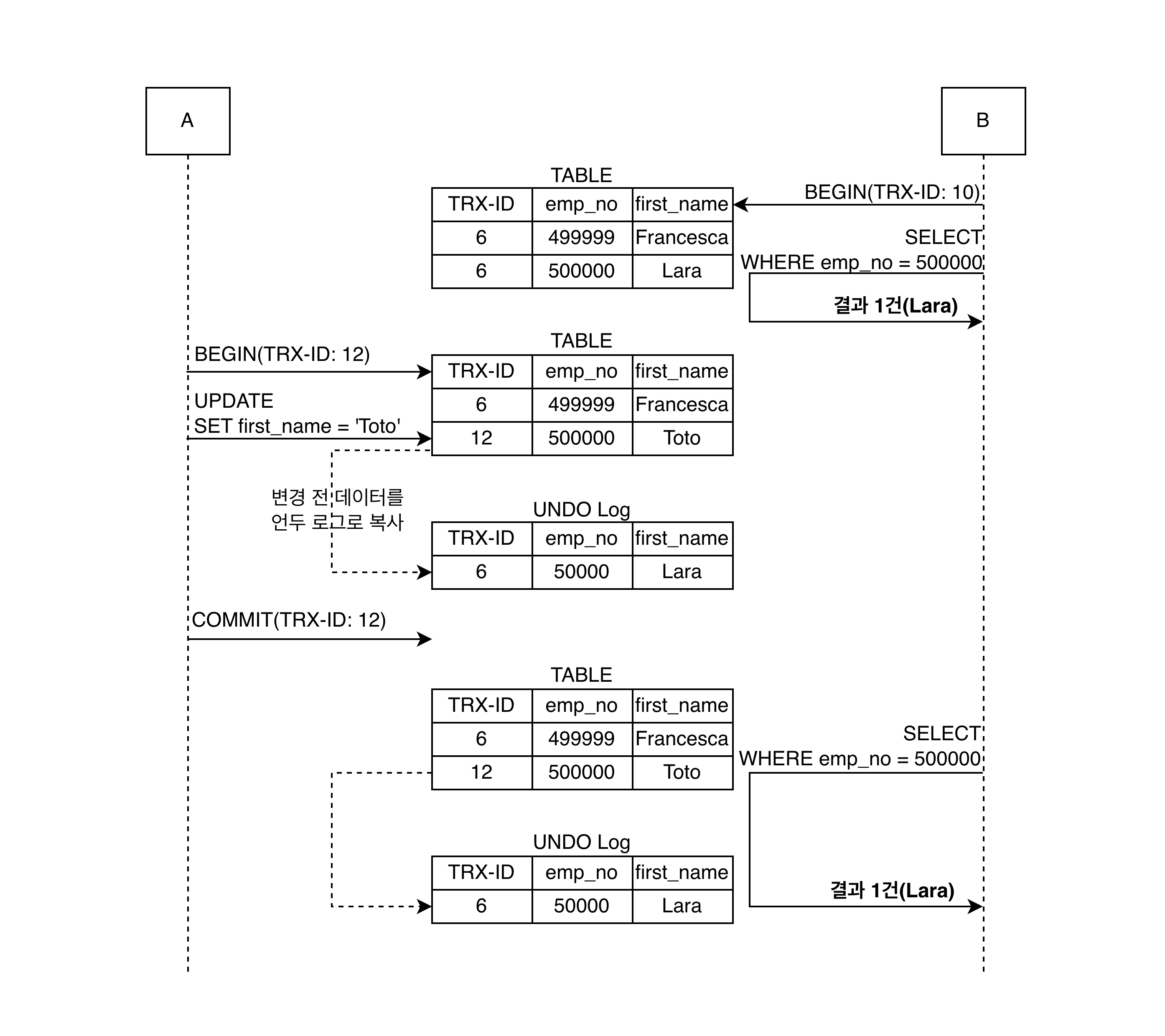
A의 트랜잭션 번호는 12, B의 트랜잭션 번호는 10이었다. A는 사원 이름은 "Toto"로 변경 후 커밋했다. 그런데 A 트랜잭션이 커밋을 했지만, B가 emp_no=500000 사원을 A 트랜잭션의 변경 전후 각각 한번씩 SELECT 한 결과 모두 같은 결과인 "Larar"를 가져온다. B가 BEGIN 명령으로 트랜잭션 시작하면서 10번이라는 트랜잭션 번호를 얻었는데 그때부터 트랜잭션 B에서 실행되는 모든 SELECT는 트랜잭션 번호가 10보다 작은 트랜잭션 번호에서 변경한 것만 보게 되는것이다.
이렇게 해당 격리수준에서는 언두 로그에 백업된 데이터들을 계속 탐색해야되기에 로그가 쌓인다면 조회 성능이 떨어질 수 있다.
MVCC는 어떻게 Phantom Read를 막는가?
MVCC가 데이터를 관리하는 핵심은 3가지가 있다.
1. 행 단위 숨겨진 칼럼 (Hidden Columns)
InnoDB의 모든 테이블에는 사용자에게 보이지 않는 두 개의 칼럼이 추가된다.
- DB_TRX_ID: 해당 행을 마지막으로 삽입하거나 갱신한 트랜잭션의 ID
- DB_ROLL_PTR: Undo Log에 기록된 이전 버전의 데이터로 가는 포인터
2. Undo Log
데이터가 변경될 때마다 이전 버전의 데이터를 저장해 두는 공간. 이 로그들이 체인처럼 연결되어 있어, 특정 시점의 데이터 상태를 재구성할 수 있게 해준다.
3. Read View (스냅샷)
트랜잭션이 시작될 때(정확히는 첫 번째 SELECT 시점 시) 현재 실행 중인 트랜잭션들의 목록을 리스팅해 둔 것. 자기를 만든 트랜잭션보다 나중에 시작된 트랜잭션이 변경한 데이터는 무시한다. 여기서 무시한다는것은 보지 않는다는 의미.
테이블에 가서 레코드의 DB_TRX_ID를 보고 자기보다 후배인 트랜잭션이 수정한 레코드면, DB_ROLL_PTR로 Undo Log 찾아가 따라가며 자신에게 '보여야 하는 버전'이 나올 때까지 과거 기록을 탐색한다.
중요한 차이점: Snapshot Read vs Locking Read
- Snapshot Read: 일반적인 SELECT는 MVCC(Read View)를 통해 Phantom Read가 발생하지 않는다.
- Locking Read:
SELECT ... FOR UPDATE나UPDATE같은 쿼리는 현재 시점의 실제 데이터를 읽어야 하므로 MVCC만으로는 부족하다. 이때는 Next-Key Lock(레코드 락 + 갭 락)을 사용하여 Phantom Read를 방지한다.
MVCC를 쓰는데도 Phantom Read가 발생하는 경우 예시
InnoDB 엔진에서는 REPEATABLE READ 격리 수준이도 팬텀 리드가 발생하는 경우가 있을수 있는데 다음과 같은 상황이다.
A가 employees 테이블에 INSERT 실행하는 도중에 B가 SELECT ... FOR UPDATE쿼리로 employees 테이블 조회시 발생하는 일이다.
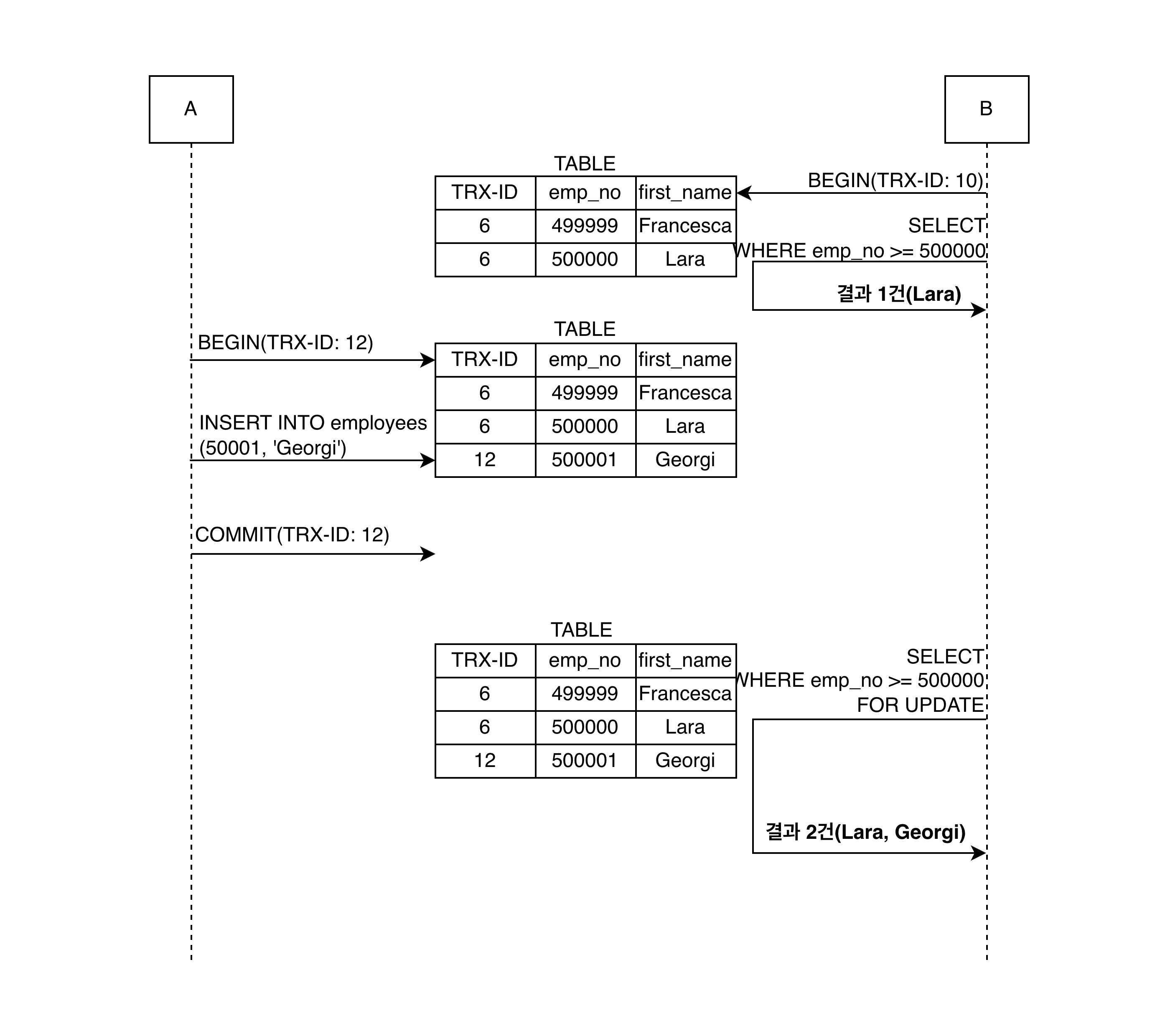
REPEATABLE READ 니까 당연히 한 트랜잭션에서의 SELECT 결과는 같아야될거같다. 하지만 서로 다르다.
이런 다른 트랜잭션에서 수행한 변경 작업에 의해 레코드가 보였다 안 보였다 하는걸 팬텀 리드라 지칭한다.
SELECT ... FOR UPDATE는 SELECT하는 레코드에 Write Lock을 걸어야 하는데, 언두 로그(레코드)에는 잠금이 불가하다.
그래서 SELECT ... FOR UPDATE, SELECT ... LOCK IN SHARE MODE로 조회되는 레코드는 언두 영역의 변경적 데이터를 들고오는게 아닌 현재 레코드의 값을 가져오게 되는것이다.