[정리] Redis Cache
캐시란?
캐시란 데이터의 원본을 보다 더 빠르게 접근할 수 있는 임시 데이터 저장소를 뜻한다. 사용자가 동일한 정보를 반복적으로 액세스할 때 원본이 아닌 캐시에서 데이터를 가져옴으로서 원본 저장소의 부하를 줄일 수 있다.
다음 조건을 만족시킬때 좋은 효과를 본다.
- 원본 저장소에서 원하는 데이터 찾기 위해 검색 시간이 길때
- 원본 저장소에서 항상 계산을 통해 데이터를 가져올 때
- 캐시에 저장 될 데이터는 잘 변하지 않는 데이터 일 때
- 캐시에 저장 될 데이터는 자주 검색되는 데이터 일 때
캐시 역할로서의 레디스
사용이 간단
단순히 키-값 형태로 저장하므로, 데이터를 저장하고 반환하는게 간단하며 자체적으로 다양한 자료구조를 제공해서 애플리케이션에서 자주 쓰던 list, hash 등 자료구조를 변환하는 과정 없이 바로 레디스에 저장 가능하다.
인 메모리 데이터 저장소
인 메모리 데이터 저장소라 검색과 반환이 매우 빠르다. RDBMS 에서는 일단 테이블의 특정 데이터 찾으려면 디스크에 접근해 데이터를 검색해와야한다. 하지만 레디스는 모든 데이터가 메모리에 올라와 있기 때문에 데이터 접근이 매우 빠르다.
자체 HA 지원
자체적으로 고가용성 기능을 가지고있다는 것이 큰 장점이다. 일부 캐싱 전략에서는 캐시에 접근이 안되면 곧바로 서비스의 장애로 이어질 수 있는 만큼 이런 자체 고가용성 기능이 유용하다.
레디스의 센티널 또는 클러스터 기능을 사용하면 마스터 노드의 장애를 자동으로 감지해 페일오버를 발생시키기 때문에 운영자, 개발자의 개입 없이 캐시는 정상으로 유지될 수 있어 가용성이 높아진다.
스케일 아웃
레디스 클러스터를 사용하면 캐시의 스케일 아웃을 쉽게 처리할 수있다. 서비스의 규모에 따라 캐시의 규모를 키워야 될 수도 있는데 레디스의 자체 샤딩 기능인 클러스터를 쓴다면 수평 확장을 쉽게 할 수 있다.
캐싱 전략
읽기 전략 - look aside
가장 일반적으로 배치하는 방법.
- 찾고자 하는 데이터가 먼저 캐시에 있는지 확인
- 캐시에 데이터가 있으면 읽어온다.(캐시 히트)
- 찾고자 하는게 없다면(캐시 미스), 직접 데이터베이스에 접근해 데이터를 가져온뒤 이 데이터를 캐싱시킨다.
look aside 구조는 레디스에 문제가 생겨도 서비스 장애로 이어지지 않고 데이터베이스에서 데이터를 가지고 올 수 있다는 것. 물론 커넥션이 데이터베이스로 몰리니 부하가 발생해 애플리케이션 성능에 영향을 미칠 수는 있다.
lazy loading 이라고도 불리는 기법.
캐시 워밍
만약 레디스를 새로 기동한다면 내부의 데이터는 아무것도 없어서 애플리케이션은 데이터를 찾기 위해 데이터베이스에 접근하는 과정때문에 서비스가 원할하지 않게 될 수 있다.
이를 방지하기 위한 방법으로 미리 캐시로 데이터를 밀어주는 작업이 바로 캐시 워밍.
쓰기 전략과 캐시 일관성
캐시는 원본 데이터의 복사판. 따라서 원본 데이터와 동일한 값을 가지도록 유지하는것이 필수적이다. 만약 원본이 변경될 때 캐시는 변경이 안된다면 데이터 불일치가 일어난다. Cache Inconsistency 라 불림.
캐시를 이용한 쓰기 전략은 대표적으로 3가지가 있다 하나씩 살펴보자.
쓰기 전략 1. write through
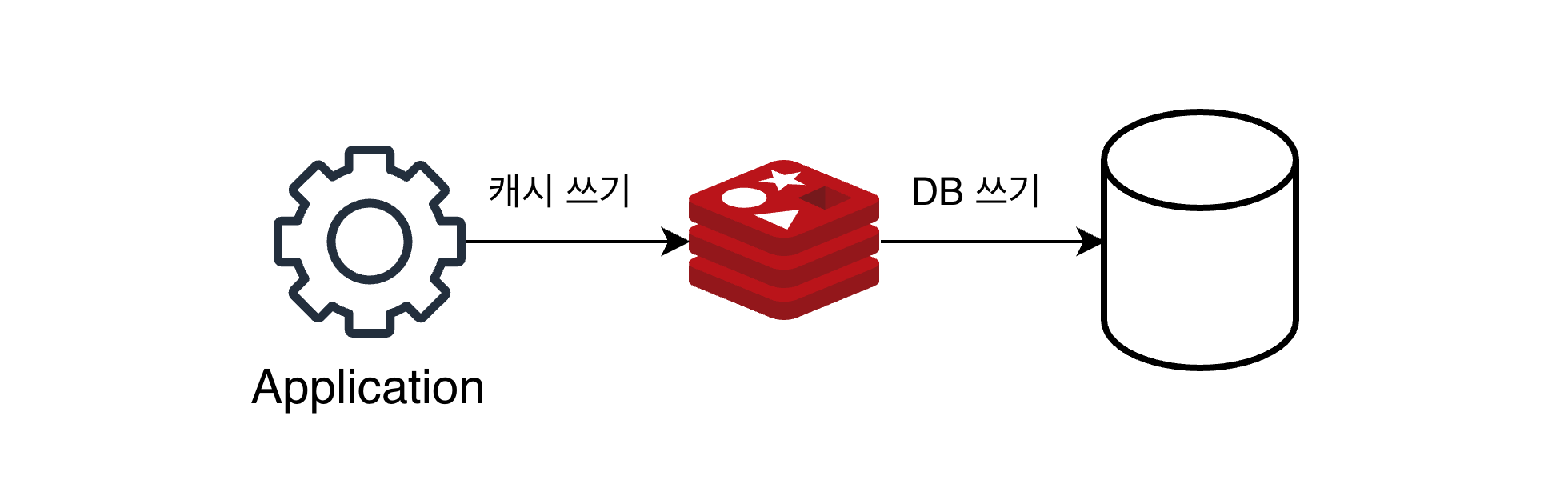 write through 방식은 데이터베이스에 업데이트 할 때마다 매번 캐시에도 함께 업데이트하는 방식.
write through 방식은 데이터베이스에 업데이트 할 때마다 매번 캐시에도 함께 업데이트하는 방식.
항상 캐시에 최신 데이터 유지되는 장점이 있지만 매번 2개의 저장소에 저장되야 해서 쓰기 리소스가 많이 든다.
캐시는 다시 사용될 만한게 저장되는게 좋은데 이 방식은 무조건 업데이트가 되어버리니 리소스 낭비 가능성이 있다. 따라서 이 방식을 쓸때는 만료 시간(TTL)을 사용할 것이 권장된다.
쓰기 전략 2. cache invalidation
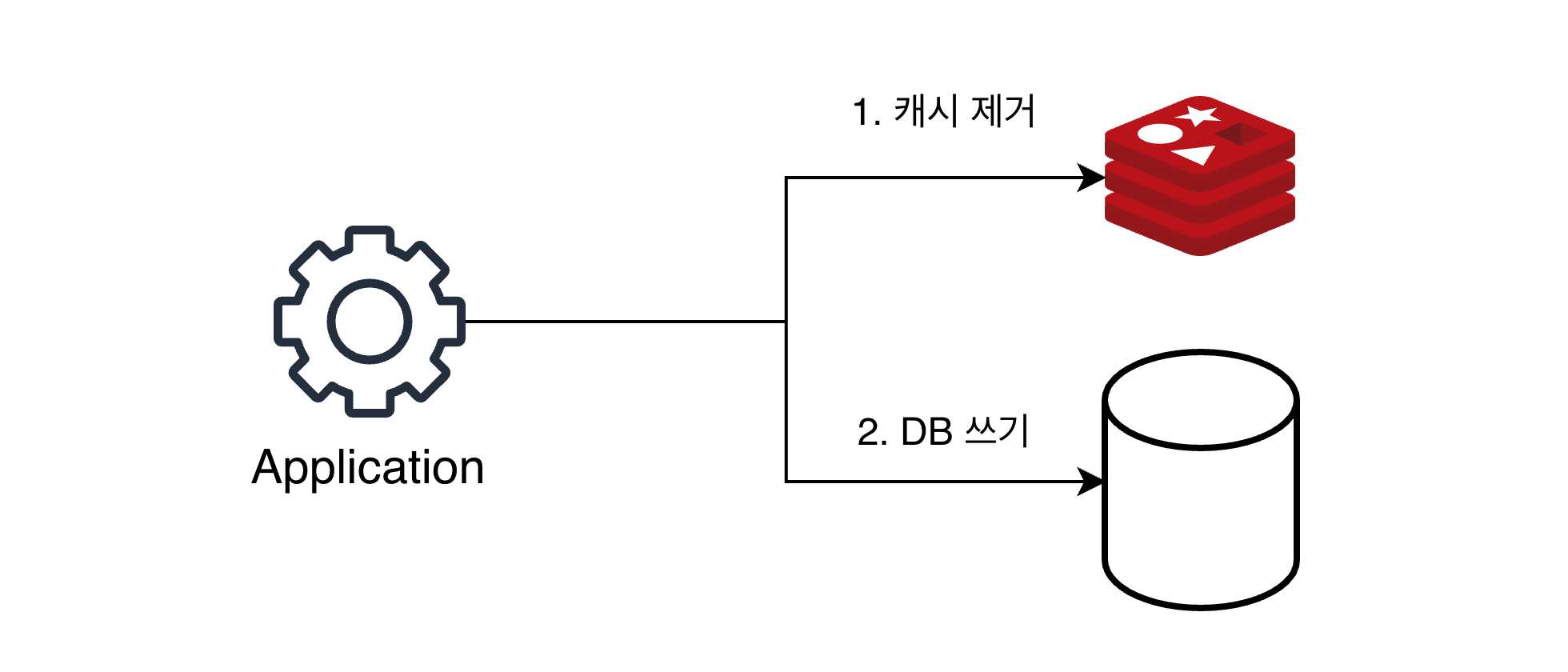 그림 처럼 cache invalidation 은 데이터베이스에 값을 업데이트할 때 마다 캐시에서는 데이터를 삭제하는 전략.
그냥 삭제해버리는게 저장 및 업데이트하는것 보다 리소스를 적게 쓰기에 앞선 write through 의 단점을 보완했다 할 수 있다.
그림 처럼 cache invalidation 은 데이터베이스에 값을 업데이트할 때 마다 캐시에서는 데이터를 삭제하는 전략.
그냥 삭제해버리는게 저장 및 업데이트하는것 보다 리소스를 적게 쓰기에 앞선 write through 의 단점을 보완했다 할 수 있다.
쓰기 전략 3. write behind(write back)
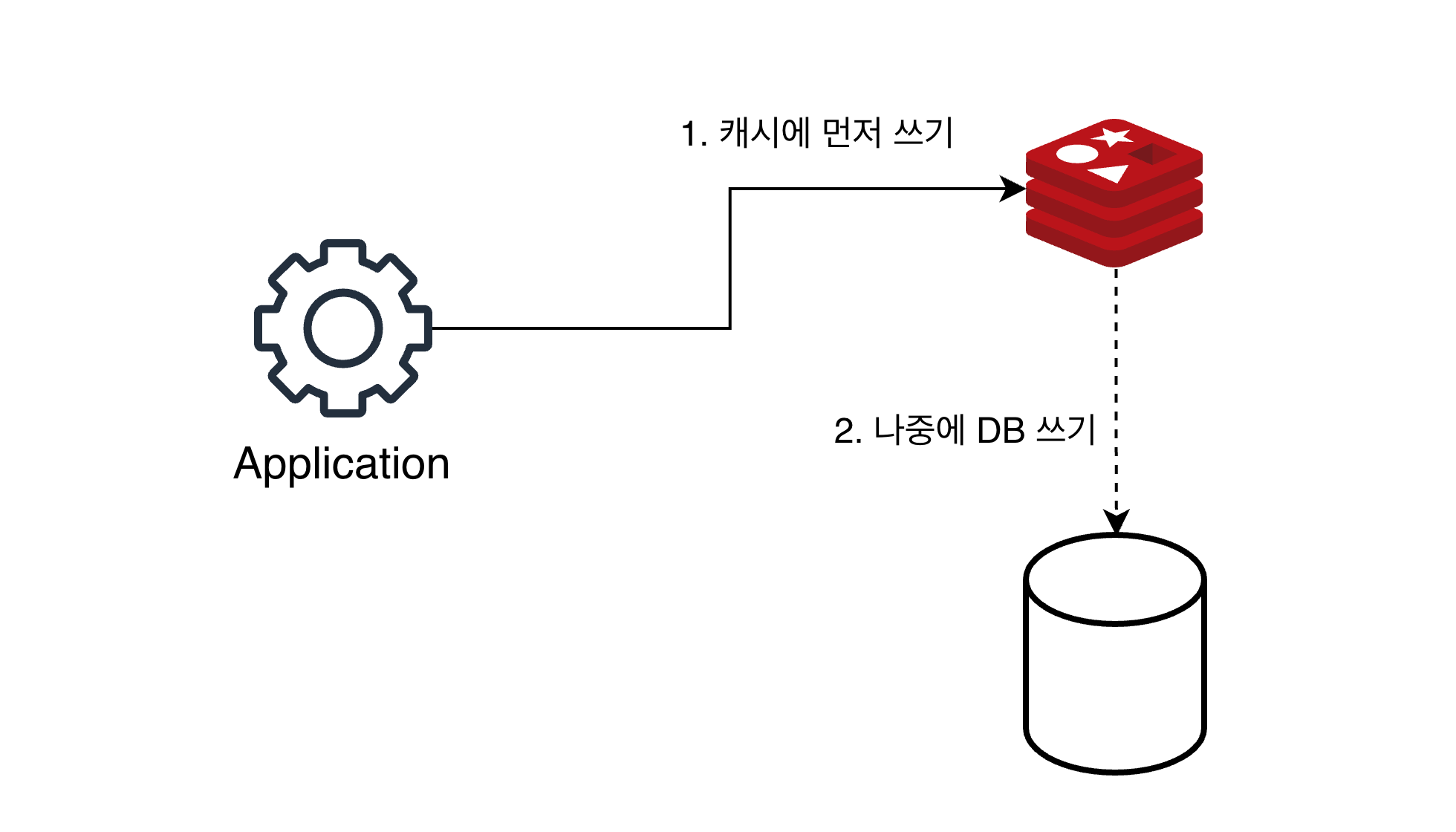 쓰기가 빈번하다면 write behind 방식을 고려해볼 수 있다.
쓰기가 빈번하다면 write behind 방식을 고려해볼 수 있다.
데이터베이스에 대량으로 쓰기를 하면 많은 디스크 IO를 유발해 성능저하가 발생할 수 있다. 이를 방지하기 위해 캐시에 먼저 업데이트 한 뒤, 이후에 건수나 특정 시간 간격을 세팅해서 비동기적으로 데이터베이스에 업데이트 하는 방식이다.
저장되는 데이터가 실시간성이 중요하지 않을때 적합하다. 예를 들어 유튜브의 영상 좋아요 수는 실시간 집계가 필요치 않다. 좋아요를 누른 데이터를 우선 레디스에 저장해둔 다음 5분 간격으로 이를 집계해 데이터베이스에 저장하는 과정을 거친다면 데이터베이스에 부하를 덜 주는 방식이 될 수 있다. 물론 캐시가 날아가는 경우 최대 5분동안의 데이터가 없어질 수 있다는건 감안해야한다.
캐시에서 데이터 흐름
캐시는 사용자가 자주 사용할 만한 데이터를 갖고와서 임시로 저장하는 장소. 따라서 원본 저장소보다는 적은 양을 보관한다.
따라서 캐시 용량이 가득 차지 않게 일정양을 유지해야 하며 계속 새로운 데이터가 저장되고 기존 데이터는 삭제될 수 있도록 관리해야한다.
이를 위해 레디스를 캐시로 쓸 때는 데이터를 저장함과 동시에 적절한 TTL을 지정하는게 좋다.
만료 시간
레디스에서 만료 시간(TTL, Time To Live)는 특정 키에 대한 만료시간을 지정할 수 있다. 일반적으로 초 단위로 세팅됨.
레디스에 저장된 키에 EXPIRE 커맨드를 쓰면 만료 시간을 지정할 수 있다. TTL, EXPIRE 커맨드는 초 단위로 동작하며, PTTL,PEXPIRE 커맨드는 밀리세컨드 단위로 동작한다.
EXPIRE 로 TTL 지정한다음에 INCR이나 RENAME을 하더라도 TTL은 변경안된다. 하지만 기존 키에 새로운 값을 저장해 키를 덮어 쓸 때는 이전에 설정한 TTL은 유지되지 않고 사라진다.
레디스에서 키가 만료되었다고 바로 삭제되는건 아니다. 키는 passive 방식과 active 방식 이 두가지로 삭제된다.
- passive: 클라가 키에 접근하고자 할 때 키가 만료되었으면 메모리에서 수동 삭제됨. 사용자가 접근할 때에만 수동으로 삭제되서 passive라 한다. (사용자가 접근 않는 키는 계속 메모리에 있게됨)
- active: TTL 값이 있는 키 중 20개를 랜덤으로 선택해서 모두 메모리에서 삭제한다. 만약 25% 이상의 키가 삭제됐다면 다시 20개의 키를 랜덤하게 뽑은뒤 확인하고, 아니라면 뽑아놓은 20개의 키 집합에서 다시 확인한다. 이런 과정을 1초에 10번씩 수행. 만료된 키를 곧바로 삭제 않기에 키를 삭제하는 리소스 아낄수있지만, 그만큼 메모리를 더 사용한다. 최악의 경우 1/4가 이미 만료된 키 값일수도 있다;
메모리 관리와 maxmemroy-policy 설정
TTL로 관리를 해도 너무 많은 키가 저장되면 메모리가 가득 차는 상황이 발생할 수 있다. 메모리의 용량을 초과하는 데이터가 저장되려하면 레디스는 내부 정책을 사용해 어떤 키를 삭제할 지 결정한다.
레디스에는 최대 저장 용량을 설정하는 maxmemory 설정과 이걸 초과할 때의 처리 방식을 결정하는 maxmemory-policy 설정값을 이용해 메모리를 관리한다.
이 정책이 뭐가 있고 동작 방식을 살펴보자.
Noeviction
기본값은 noeviction 이다. 이 정책은 데이터가 가득 차더라도 임의로 데이터를 삭제말고 에러를 반환하도록 하는 것.
하지만 캐시에 데이터 저장이 안되 에러가 발생할 경우 로직에 따라 장애 상황으로 번질수 있으며 이런 상황이 오면 관리자가 직접 레디스의 데이터를 지워야 할 수 있어서 권장하지 않는 정책이다.
데이터 관리를 애플리케이션단에서 관리하겠다는 의미이며, 개발자가 직접 코드로 eviction을 관리하고 싶을 때 이 정책을 쓰면 될것이다.
LRU eviction
데이터가 가득 찼을때 가장 최근에 사용되지 않은 데이터부터 삭제하는 정책. LRU(Least Recently Used)이름 그대로인 정책. 가장 최근에 사용되지 않은 데이터는 이후에도 액세스 가능성이 낮다는 가정을 전제로한다.
레디스는 LRU 알고리즘을 이용한 두 가지 설정값을 가지고있다.
- volatile-lru: 만료 시간이 설정되 있는 키에 한해서 LRU 방식으로 키를 삭제한다. 만약 임의적인 방식으로 삭제되면 안되는 값에 대해 만료 시간 지정하지 않는다면 이 방식쓰는게 적합할 수 있다.
단 이건 장애 유발가능성이 있는데, 만약 레디스의 모든 키에 만료 시간이 없다면 이는
noeviction과 같은 상황이 된다.
- allkey-lru: 공식문서에서는 레디스를 캐시로 쓸 때 잘 모르겠으면
allkey-lru를 권장한다. 이 방식은 모든 키에 대해 LRU 알고리즘을 적용해 삭제하기에 적어도 메모리가 꽉 찼을 때 에러 반환은 안된다.
LFU eviction
Least Frequently Used 란 가장 자주 사용 되지 않은 데이터부터삭제하는 정책. 자주 사용되지 않은 데이터는 나중에도 액세스 될 가능성이 낮을 것이라는 가정을 전제한다.
LRU 와 유사하지만 키를 액세스하는 패턴에 따라 우선순위가 유동적을 바뀐다는 점에서 특정 케이스에서는 LRU보다 효율적일 수도 있다.
이것 또한 2가지 설정값 가진다.
- volatile-lfu: 만료 시간 있는 키에 한해서 LFU eviction 적용.
volatil-lru처럼 특정 상황에서 장애 유발 가능성 존재 - allkey-lfu: 모든 키에 대해 LFU 적용해 데이터 제거한다
레디스에서 키 삭제를 위해 사용되는 LRU, LFU 는 모두 근사 알고리즘으로 구현됐다. 키를 정확하게 찾아내는 것에 너무 많은 자원을 쓰는걸 방지하기 위함. 일반적으로
noeviction을 쓰지않는한 데이터는 어느순간 삭제될 수 있다는 가정하에 알고리즘이 동작한다. 따라서 정확한 계산보다는 근사치로 찾아내 삭제하는 방법으로 효율적으로 동작한다.
random eviction
레디스의 저장된 키 중 임의로 골라 삭제한다. 앞서 소개한 알고리즘들을 안써서 삭제 될 키 값을 계산안해도 되는 장점이 있다. 하지만 LRU, LFU 는 근사 알고리즘을 사용하기에 큰 리소스를 안써서 굳이 부하를 줄이기 위한 이유로는 random eviction을 권장하지 않는다.
- volatile-random: 만료 시간이 설정되어 있는 키에 한해 랜덤하게 키 삭제
- allkeys-random: 모든 키에 대해 랜덤하게 키 삭제
volatile-ttl
만료 시간이 가장 작은 키를 삭제한다. 삭제 예정 시간이 얼마 남지 않은 키를 미리 삭제하는 정책. 이 또한 근사 알고리즘을 쓴다.