TTL로 인한 Cache Stampede
동시에 캐시가 만료되는 상황
다음과 같은 상황을 가정해보겠다.
- 레디스(Redis)를 캐시 서버로 사용
- Look Aside 방식의 캐시 전략 채택
- 우연히 다수의 레디스 키에 동일한 TTL이 설정됨
이런 상황에서 만약 TTL 설정때문에 대부분의 키가 무효화 되는 순간, 동시에 여러 조회 요청이 오면 어떻게 될까?
문제발생: 데이터베이스 부하 by Cache Stampede
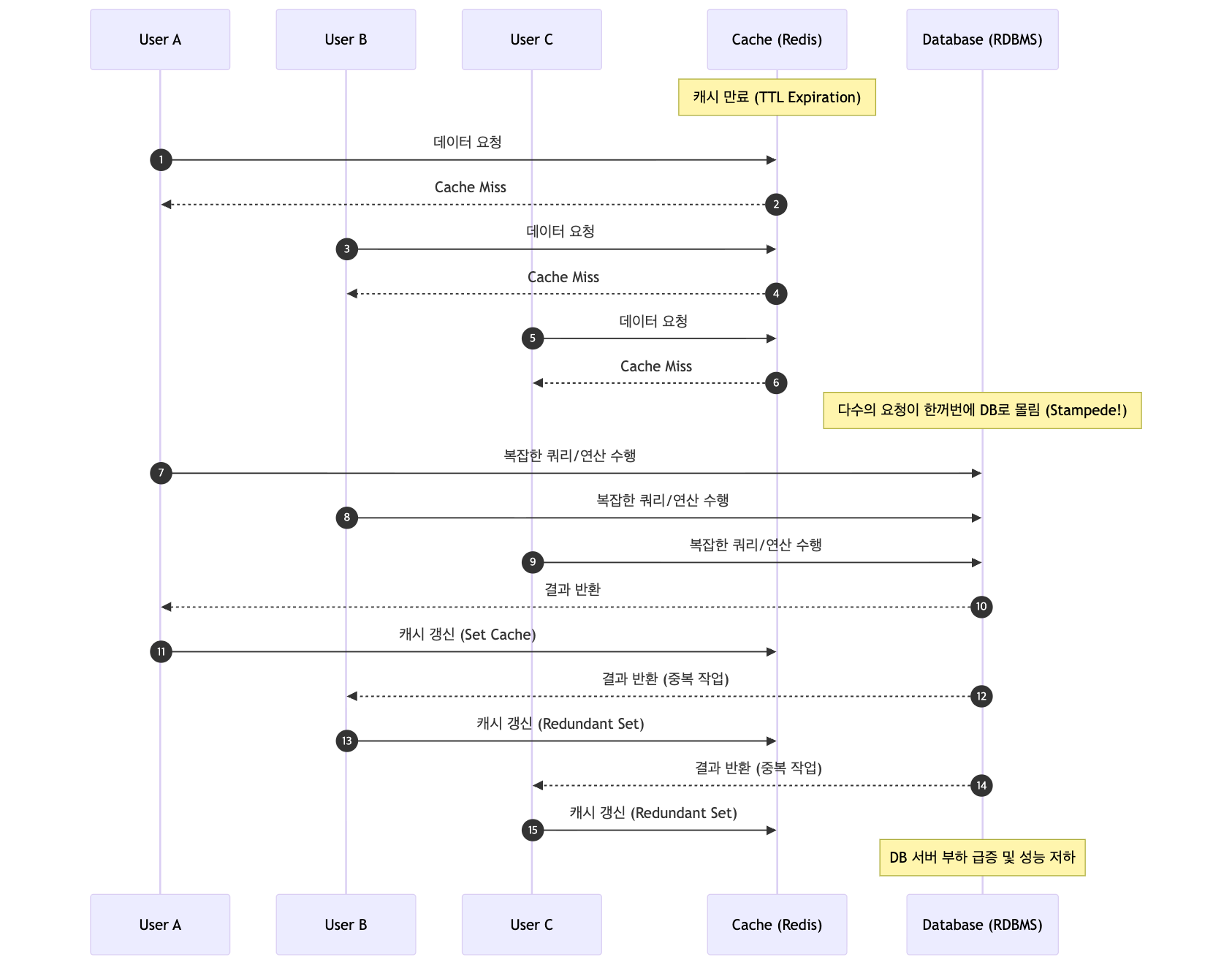 Look Aside 방식을 쓰면 캐시가 없을 때 애플리케이션이 직접 DB를 조회한다.
TTL이 만료된 그 짧은 찰나에 수많은 요청이 DB로 몰리게 됨으로서 DB서버는 갑작스러운 부하를 받게 된다.
Look Aside 방식을 쓰면 캐시가 없을 때 애플리케이션이 직접 DB를 조회한다.
TTL이 만료된 그 짧은 찰나에 수많은 요청이 DB로 몰리게 됨으로서 DB서버는 갑작스러운 부하를 받게 된다.
이를 캐시 스탬피드(Cache Stampede) 라 지칭한다.
계층별로 발생할 수 있는 문제를 생각해보자.
DB 층에서는 이런 현상이 일어날 수 있다.
- 커넥션 풀 고갈
- 급격한 쿼리 수행으로 CPU 사용량 상승
애플리케이션 층에서는 이런 현상이 일어날 수 있다.
- DB응답 대기로 인한 스레드 풀 고갈
- 타임아웃으로 인한 실패 응답 및 서비스 장애까지 전이
- 실패한 유저들의 재시도로 인한 요청 누적(Retry Storm)
사용자 경험 층에서는 이런 현상이 일어날 수 있다.
- 빠른 응답이 안와서 불쾌한 경험
- 여러번 재시도 함에도 정상 작동안함으로서 서비스의 신뢰성 하락
단순히 TTL 설정 하나 잘못했을 뿐인데, 시스템 전체의 가용성이 연쇄적으로 무너짐을 볼 수 있다.
이번 글에서는 이 불상사들의 시발점인 캐시 스탬피드를 어떻게 방지할 수 있는지에 관해 집중적으로 탐구해보겠다.
해결법 1: Jitter
이 방식은 캐시가 대량으로 생성될 때 만료 시점이 한꺼번에 몰리는 것을 방지하는 데 탁월하다.
이 지터 방식은 이런 공식을 쓰는것이라 이해하면 쉽다.
TTL = 기본 설정 시간 + random_jitter
구현이 매우 간단하다.
신규 캐시 데이터를 저장할때, random_jitter 값을 무작위로 생성항 TTL 설정값에 더해주기만 하면된다.
이렇게 하면 키들이 서로 다른 시점에 만료되므로 캐시 대량 생성이 발생했을때, 한꺼번에 캐시가 만료되는 현상이 어느정도 방지될 것이다.
해결법 2: 적절한 TTL 설정
'적절'한 값을 찾기위해서 살펴볼 것들을 정리해봤다.
데이터 성격에 따른 TTL 설정
- 정적 데이터 (이미지 경로, 설정값 등): 변경 빈도가 낮으므로 TTL을 길게 설정하고, 데이터 변경 시 캐시를 명시적으로 무효화하는 전략을 생각해볼 수 있다.
- 준실시간 데이터 (조회수, 게시글 목록 등): 트래픽이 몰리는 시점에 DB 부하를 막아주는게 가장 중요하다 생각된다. TTL을 짧게 가져가되 Jitter 전략도 같이 해주자.
모니터링 지표들을 통한 TTL 설정
- Cache Hit Ratio: 캐시 히트율이 너무 낮다면 TTL이 너무 짧거나 캐시 키 설계가 잘못된 것임을 파악하자.
- P99 Latency (DB): 캐시가 만료되는 시점에 DB 응답 속도가 튀는지 모니터링.
- Load (DB): 캐시 만료 시점에 DB의 CPU/Memory 사용량을 모니터링.
이런 지표들을 모니터링하며 특정 지표가 튀거나 할때 개발자가 직접 TTL을 조절해주는게 좋다 생각한다.
해결법 3: PER 알고리즘
PER(Probabilistic Early Recomputation) 알고리즘은 캐시가 만료되기 직전에 "지금 미리 갱신할까?"를 확률적으로 결정하는 방식이다.
캐시 스탬피드 현상을 확률적 조기 재계산으로 완화시켜주는 알고리즘인 것.
PER 알고리즘의 논문에 수많은 이론이 있지만 간단히 다음과 같이 요약이 된다한다.
currentTime - ( timeToCompute * beta * log(read()) ) > expiry
- currentTime: 현재 남은 만료 시간
- timeToCompute: 캐시된 값을 다시 계산하는데 걸리는 시간
- beta: 기본적으로 1.0 보다 큰값으로 설정 가능. 이 값이 클수록 "더 일찍, 더 자주" 조기 갱신이 일어남.
- rand(): 0과 1 사이의 랜덤 값을 반환하는 함수
- expiry: 현재 만료 예정 시각
log(read())는 항상 0 또는 음수다. read()가 0 ~ 1 사이기 때문.
timeToCompute * beta * log(read())는 무작위성 값.
이 값은 항목의 만료 여부에 영향 끼친다.
만료시간이 가까워 질수록 currentTime 과 expire 사이의 갭이 작아지며 rand() 함수가 반환한 무작위 값에 의존하기에 조건이 참이될 확률이 높아진다.
이건 만료 시간이 점점 다가올 때 만료된 캐시 항목을 확인하게 되는 것 의미한다.
위 조건문에서 true 반환받은 애플리케이션은 데이터를 다시 갱신하기 위해 데이터베이스로 이동하게 된다.
만료 시간에 가까워 질 수록 true 확률이 증가하므로 불필요한 재계산을 방지하는 효율적인 방법일 수 있는것이다.
PER 알고리즘 실제 작동 흐름
이 알고리즘을 적용하려면 레디스에 단순히 값만 저장하는 게 아니라, 메타데이터를 함께 저장해야 한다.
- 데이터 저장 시: 실제 값과 함께
expiry(만료 시각),timeToCompute(데이터를 생성하는 데 걸린 시간)를 함께 저장한다. - 데이터 조회 시 (Redis Get):
- 레디스에서 데이터를 가져온다.
- 가져온 데이터의
expiry와timeToCompute를 사용하여 PER 식(currentTime - (Gap) > expiry)을 계산한다. - 조건이 true이면: 아직 레디스에 데이터가 남아있더라도, DB에서 새 데이터를 조회해 레디스를 갱신한다.
- 조건이 false이면: 그냥 레디스에 있던 데이터를 그대로 반환한다.