B-Tree 자료구조

서론
DB 성능에 관해 조금이라도 관심이 생기면 반드시 만나게 되는 개념이 바로 '인덱스'다. 이 인덱스를 구현하는 데 핵심적으로 쓰이는 B Tree 자료구조에 관해 이번 글에서 정리해보려 한다.
'쉬운코드'님의 B Tree 강의 내용을 기반으로 나만의 언어로 재구성해 본 글이다.
B Tree 특징
B Tree에서는 한 노드에 여러 값을 넣을 수 있게 설계가 되있다. 이 글에서 노드에 들어가는 값(데이터)을 key 라 지칭하고 진행하고자 한다.
B Tree는 Balanced Tree의 약자로 말 그대로 균형 잡힌 트리라는 의미다. 또한 Binary Serach Tree의 탐색 특징을 그대로 가지고 있다. BST와 차이점이라면 노드에 key 값이 여러개 들어갈 수 있어 트리의 높이를 BST와 비교해 획기적으로 줄일 수 있다는 점이다.
부모노드에 key 값이 k개 있다면 자식 노드는 k+1 개 둔다.
예를 들어 부모 노드에 key 값을 10, 20이 있다면 자식 노드는 ? < 10 | 10 < ? < 20 | 20 < ? 의 규칙을 가지는 것으로 여기면 된다.
또한 모든 서브 트리들도 이 특징을 그대로 유지하며 확장된다.
부모 노드의 key 들은 오름차순으로 정렬된다. 이 정렬된 순서에 따라 자식 노드들의 key 값 범위 또한 결정된다. 자식 노드의 최대 개수를 조절할 수 있다는 부분이 BST와 차별점이라 볼 수 있다.
B Tree 4가지 파라미터
B Tree에서 최대 몇 개의 자식 노드를 가질 것인지가 가장 중요한 파라미터다.
- M: 각 노드의 최대 자식 노드 수
- 최대 M개의 자식 노드를 가질 수 있는 B Tree를 "M차 B Tree"라 부른다.
- M - 1: 각 노드의 최대 key 수
- ⌈M/2⌉: 각 노드의 최소 자식 노드 수(제외: 루트 노드, 리프 노드)
- ⌈M/2⌉ - 1: 각 노드의 최소 key 수(제외: 루트 노드)
⌈ ⌉ 표시는 소수점을 올림 한다는 의미
B Tree 데이터 추가 과정
B Tree 데이터 추가 2가지 핵심
- 추가는 항상 리프 노드에 한다.
- 노드가 넘치면(노드의 key 개수가 M-1을 넘어서면) 가운데(median) key를 기준으로 좌우를 분할하고 가운데 key는 부모 노드로 승진시킨다.
B Tree 데이터 추가 예시
B Tree 시뮬레이션 추천드린다. 직접 눈으로 B Tree에 데이터를 추가, 삭제하면서 트리가 어떻게 분할되는지 확인하면 이해가 빨라지는 것을 직접 체감했다.
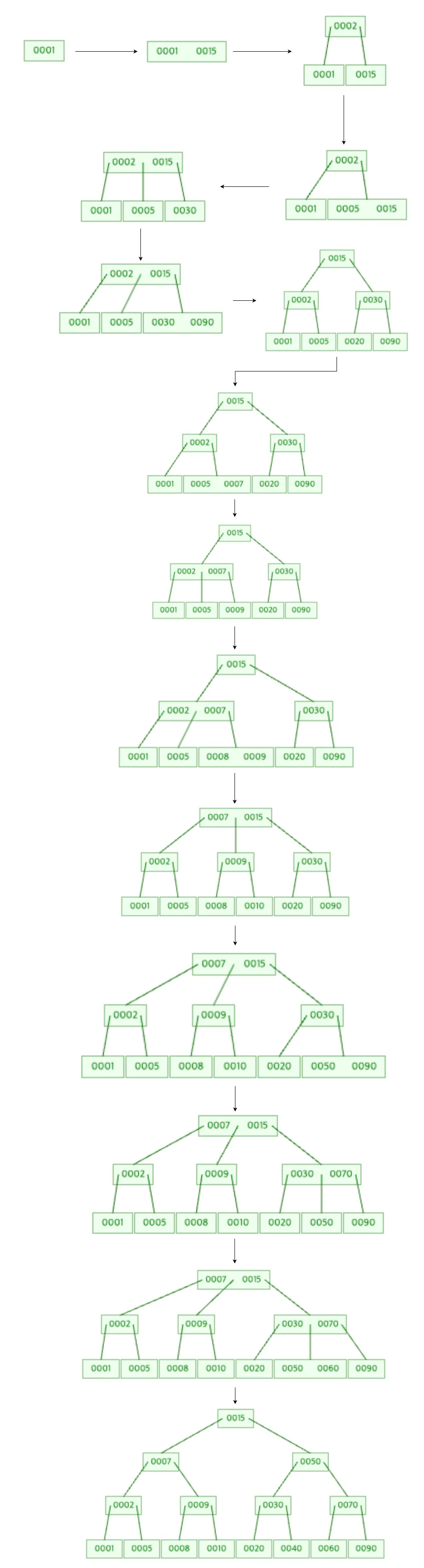
중간 정리: 추가
- B Tree 리프 노드는 항상 같은 레벨이다.
- B Tree는 Balanced Tree다.(시간복잡도: O(log n))
- BST는 Balanced Tree가 아니어서(균형 강제 X) 노드가 편향(skewed)될 경우 O(n)까지 성능 저하될 수 있지만, B Tree는 이를 구조적으로 방지한다.
B Tree 데이터 삭제 과정
삭제도 항상 리프 노드에서 발생한다. "내부(Internal) 노드의 데이터도 삭제되는데 무슨 소리지?" 싶을 수 있지만, 내부 노드의 데이터를 삭제할 때도 결국 리프 노드와 위치를 바꿔서 처리하기 때문이다.
삭제 시 다음의 제약이 있다.
B Tree 데이터 삭제 핵심 제약
- 리프 노드의 key를 삭제 후, 해당 노드의 key 수가 최소 key 수보다 작아졌다면 재조정을 할 것
⌈M/2⌉ - 1: 각 노드의 최소 key 수(제외: 루트 노드)
재조정 시에는 다음 우선순위를 고려한다.
- 형제 지원: key 수가 여유있는 형제 노드들에게 지원 받기. 로테이션이 발생한다.
- 부모 지원 + 병합: 1번이 불가하면 부모의 key를 내려받고 형제와 합치기.
- 연쇄 재조정: 2번 수행 후 지원을 해준 부모가 최소 key 수를 못지키게 되었다면, 그 노드에서 다시 재조정 수행.
삭제 과정은 쉬운 코드: B-Tree 삭제 방식 영상을 통해 직관적으로 이해하는 것을 추천드린다. 단순히 형제에게 값을 가져오는 것이 아니라, 오름차순 정렬 상태를 유지하기 위해 부모의 key를 거쳐 이동하는 '회전' 개념이 핵심.
그럼에도 불구하고 내 나름의 글로 설명해보자면 좌, 우 중 여유있는 형제에게 key를 무작정 받는게 아니라 시계방향, 반시계방향으로 부모 key까지 고려해서 회전을 한다고 생각하면된다. 이는 오름차순 제약을 지키기 위함이다. 우측 형제의 가장 작은 key를 본인이 받으면 우측 형제가 가진건 결국 부모의 특정 key보다 큰 값인데 그게 그 key값의 좌측에 있는 본인한테로 온다면 밸런스가 꺠지게 되기 때문이다.
또한, 2번 사항은 부모가 가진 key 값을 하나 자식에게 주고 받은 자식은 이제 형제중 하나와 합쳐지는 것이다. 이때 부모는 key를 줬으니 최소 key 개수를 못채울 경우가 생길 수 있는데 이때는 부모 노드에서 재조정을 다시 시행하는 것이다.
B Tree 내부 노드 삭제 방법
비 리프 노드를 삭제할 때는 해당 key의 선임자(Predecessor) 또는 후임자(Successor)인 리프 노드의 key와 위치를 바꾸면 된다.
- 선임자: 삭제할 key보다 작은 값들 중 가장 큰 값 (좌측 서브트리의 최우측 노드)
- 후임자: 삭제할 key보다 큰 값들 중 가장 작은 값 (우측 서브트리의 최좌측 노드)
이렇게 위치를 바꾸면 결국 삭제는 리프 노드에서 일어나는 형태가 된다.
중간 정리: 삭제
- 삭제는 항상 리프노드에서 발생한다.
- 내부(internal) 노드의 경우 전임자/후임자와 위치를 바꾸고 삭제한다.
- 삭제 후, 삭제 과정에 참여한 노드중 최소 key 개수를 만족못하는 노드 있으면 재조정한다.
왜 index로 B Tree 계열의 자료구조는 쓰는가?
B Tree 계열은 avg case, worst case 모두 O(log n)을 보장한다.
BST 경는 편향된 형태에서는 O(n) 이라는 상대적으로 느린 성능이 나온다. 이를 보완하기 위해 AVL, Red Black Tree 같은 자료 구조가 Balance를 유지하며 이를 보완하며 O(log n)을 보장한다.
이렇게 AVL 트리나 Red-Black 트리도 O(log n)을 보장하는데, 왜 하필 DB는 B-Tree를 선택한것일까?
컴퓨터 시스템 관점
OS는 보조 기억 장치(세컨더리 스토리지)에서 데이터를 읽을 때 블록(Block) 단위 또는 페이지(Page) 단위로 데이터를 읽고 쓴다. 이 단위들은 file system이 데이터를 읽고 쓰는 논리적인 단위다. 보통 메인 메모리에 2의 제곱(4KB, 8KB, 16KB 등) 단위로 올린다.
DB 관점
DB 성능의 핵심은 디스크 I/O를 얼마나 줄이느냐에 있다. B Tree는 한 노드에 많은 key를 담을 수 있습니다. 이는 하나의 노드 = 하나의 블록으로 대응시키기에 매우 유리하다.
디스크 I/O 최소화 하기위해 읽어들이는 Block에 노드의 key 값들이 같이 있는것에 유리하기에 디스크 접근이 상대적으로 작아질수 있다!
한 번의 디스크 접근(1 Block 읽기)으로 많은 정보를 메모리에 올릴 수 있고, 트리의 높이 자체도 BST 계열보다 훨씬 낮기 때문에 결과적으로 디스크 접근 횟수를 획기적으로 줄일 수 있다.
Self-balancing BST(AVL 등)가 노드 하나에 하나의 key만 담아 높이가 깊어지는 것과 달리, 한 노드에 여러 key를 담아 '옆으로 넓게' 펼친 B-Tree가 대량의 데이터를 다루는 DB 시스템에 최적인 이유인 것.